

1. 서 론
2. 클라우드 컴퓨팅
2.1 클라우드 컴퓨팅 개요
2.2 상업용 클라우드 서비스
3. 클라우드 기반의 수치모델 처리성능 분석
3.1 수치모델 성능분석용 소프트웨어
3.2 해양수치모델
4. 수치모델 성능 결과
4.1 표준 벤치마크 성능
4.2 해양수치모델 성능
5. 클라우드 환경기반의 수치모델 성능분석
5.1 HW 자원 구성에 따른 성능분석
5.2 격자 크기에 따른 성능분석
5.3 ROMS 수평격자 해상도에 따른 자원 최적화 방안
6. 결론 및 토론
1. 서 론
해양수치모델은 해양의 순환과 다양한 물리적 특성 변화를 예측하고 분석하는 데 있어 폭 넓게 사용되고 있다. 수치모델의 성능이 개선되고 컴퓨팅 성능의 개선에 따라 모의하는 분야와 영역이 점차 확대되어 사용되고 있다(Fox-Kemper et al., 2019). 전 지구를 대상으로 하는 모델의 경우, 많은 격자 수로 인해 해상도를 높여서 정밀한 모의실험을 하기 위해서는 매우 많은 양의 계산이 필요하다(GFDL, 2022). 이러한 대량의 계산량을 소화하기 위해서 과거에는 클러스터환경을 갖춘 전산실이나 수퍼 컴퓨터 센터와 같은 기관을 통해서 컴퓨팅 자원을 공급받은 경우가 많았다. 하지만 여러가지 경제적, 물리적 제약으로 인해 충분한 컴퓨터 자원을 적시에 확보하는 것은 쉬운 일이 아니었다. 정보기술(IT) 인프라가 충분하더라도 새로운 환경에 해양모델 설정을 설치하고 준비하는 데는 많은 시간이 소요된다. 해양 수치모델을 위한 IT 인프라의 준비 및 환경구성을 하는데 시간과 비용을 줄일 수 있다면 해양 수치모델을 보다 쉽고 광범위하게 사용할 수 있을 것이다.
충분한 IT 자원의 공급에 대한 필요성은 해양모델링을 비롯한 여러 대규모 해양수치모델링 분야에서 증대되고 있으며, IT 자원의 효율적인 구성과 활용을 위한 연구들이 이루어져 왔다. 최근 들어 이러한 수요를 충족시키기 위해 아마존 웹서비스(AWS), 구글의 클라우드 컴퓨팅(GCP), 네이버 클라우드 플랫폼(NCP) 등 퍼블릭 클라우드 컴퓨팅 서비스를 활용하는 방안을 많은 연구자들이 모색하고 있다(Zhuang et al., 2019). 클라우드 시스템에서 실행할 수 있는 애플리케이션의 수는 꾸준히 증가하고 있으며, 성능 저하 요인은 점차 개선되고 기술적 문제없이 애플리케이션과 수치모델링 운영을 클라우드 컴퓨팅 환경으로 이식할 수 있는지에 대한 여부와 방법을 마련하기 위한 많은 연구가 진행되고 있다(Oesterle et al., 2015; Montes et al., 2017; Zhuang et al., 2019). 상용 클라우드 서비스 초기에는 클라우드 컴퓨팅 환경에서 기후 모델의 수행과 관련된 가능성을 검증하기 위해서 여러가지 모델들의 수치 실험이 수행되었다(Oesterle et al., 2015; Chen et al., 2017; Montes et al., 2017).
클라우드 컴퓨팅은 IT 인프라 자원을 네트워크를 통해 제공하는 컴퓨팅 리소스 활용 방식으로, 사용량과 시간에 따라 수수료를 지불하는 방식이다(Mell and Grance, 2011). 제한된 인프라 자원(즉, 서버, 스토리지 및 전기)을 가진 연구원, 연구소 및 수치 해양모델 과학자들이 네트워크 접근만 가능하다면 물리적 어려움 없이 최적의 비용으로 해양 수치모델을 사용할 수 있도록 한다. 특히, 많은 종류의 3차원 해양수치모델은 메시지 전달 인터페이스(MPI)와 같은 다중CPU를 활용하는 소프트웨어 시스템을 사용하는 고성능 컴퓨팅(HPC) 환경에서 실행되어야 충분한 계산 성능을 확보할 수 있다. 해양 및 대기 수치모델 경우 연산 시 주고받는 메시지의 크기가 수평격자 혹은 수직격자 구조로 2차원이기 때문에 자료의 교환량이 많다. 서버 간의 MPI 처리에서 자료교환양이 많기 때문에 네트워크 속도가 특히 중요하다.
기존의 클러스터에서는 대규모 수치모델을 병렬로 실행하기 위해서 클러스터를 구성하는 서버들 간의 초고속 통신을 위한 스위치 방식의 통신 방식인 인피니밴드(InfiniBand)를 지원하는 네트워크 장치의 구성과 함께 MPI 등 시스템 소프트웨어를 적절히 구현해야 한다. 인피니밴드를 지원하는 스위치와 이를 지원하는 MPI 소프트웨어로 구성된 클러스터는 통신에 사용되는 CPU의 사용량을 줄이고 서버 간의 자료를 직접 전송하는 원격 메모리 액세스(RDMA) 등의 기능을 활용할 수 있어서 수치모델의 수행 성능이 확보될 수 있다(Zhuang et al., 2020). 그리고 이러한 수치모델용 전용 클러스터는 고가의 하드웨어(H/W) 및 네트워크는 일반적으로 IT 엔지니어의 지원이 필요한 경우가 많다. 이러한 장비, 인력 등의 고비용 IT 인프라 문제를 극복하기 위해 최근까지 클라우드 컴퓨팅을 활용한 병렬처리에 대하여 다양한 연구가 진행되고 있다(Zhuang et al., 2019; Cheng et al., 2022).
초기의 클라우드 환경은 전용 클러스터에 대비해서 불충분한 기능성으로 인해 병렬 처리에 몇 가지 한계가 있는 것으로 밝혀졌다(Oesterle et al., 2015). 하지만 최근 퍼블릭 클라우드 컴퓨팅 서비스인 AWS, GCP, Azure 등이 HPC의 효과적인 구현을 위해 고성능의 가상서버인 인스턴스, 이더넷 기반 고성능 네트워크를 제공하고 있으며 일부 회사는 이더넷 기반의 HPC용 서버들이 메모리를 직접 접근하는 RDMA를 가능하게 하는 프로토콜 기술 등 다양한 기술 기반을 제공하기 시작했다(Microsoft, 2015; Zhuang et al., 2020).
이러한 클라우드 컴퓨팅 서비스가 제공하는 여러가지 기능성을 활용한다면, 해양 수치모델을 수행할 수 있는 인프라를 빠른 시간에 손쉽게 준비할 수 있을 것이다. 또한 자원이 부족한 연구자들도 언제 어디서나 손쉽게 수치모델 환경을 준비하고 수치 실험을 할 수 있으며, 해당 미리 구성된 환경을 서로 공유할 수 있으며, 가상서버 단위로 구성된 환경을 이미지로 저장하고 복제하여 사용함으로써 환경 구성을 준비하는 시간도 크게 단축할 수 있다.
본 연구는 상용 클라우드에서 국내외 해양물리 연구에서 많이 활용되고 있는 해양수치모델인 Regional Ocean Modeling System (ROMS)를 활용하여 실험을 수행하여 모델의 처리 최적 성능을 분석하였다. 이더넷 기반의 고성능 네트워크, 고성능 메모리, CPU를 이용하여 상용 클라우드 컴퓨팅 환경에서 대규모 3차원 해양 수치모델을 효과적으로 구축 및 실행하는 방법을 확인하기 위해 모델이 수행되었으며, 실제 모델링 사례 연구 자료를 활용하여 클라우드 컴퓨팅 환경에서 모델을 구축하고 여러 개의 격자 해상도를 모델링 하였다. 본 연구는 북서태평양을 대상영역으로 하는 수치모델이 상업용 클라우드에서 실행되었으며 컴퓨팅 리소스 유형에 따른 다양한 성능 결과와 성능 자료의 비교 분석이 제시된다.
2. 클라우드 컴퓨팅
2.1 클라우드 컴퓨팅 개요
클라우드 컴퓨팅은 사용자가 직접 자원 신청 화면을 통해서 가상의 서버를 생성하는 셀프 서비스 프로비저닝, 신속한 프로비저닝과 같은 기능을 통해서 클라우드 컴퓨팅 서비스 회사의 원격지 자료 센터에 있는 컴퓨팅 리소스 풀에서 가상화된 서버단위인 인스턴스와 추가 결합하고 설정이 가능한 컴퓨터 리소스(예: 네트워크, 서버, 스토리지, 애플리케이션 및 서비스)를 제공한다. 사용자는 광대역 네트워크(예: 인터넷)를 통해 이러한 자원에 액세스할 수 있으며 자동 사용량 측정기능을 통해서 사용한 양만큼 과금이 청구된다. 다양한 종류의 서비스가 제공되며 관련 자원의 이용방식에 따라 분류된다. 여기에는 서버와 스토리지와 같은 자원중심의 인프라 서비스(IaaS), 자원과 더불어 사용되는 주요 소프트웨어의 구동에 필요한 엔진들이 설치되어 제공되는 플랫폼 서비스(PaaS), 그리고 사용자가 직접 사용하는 사용자소프트웨어 단위로 제공되는 소프트웨어 서비스(SaaS)로 크게 구분할 수 있다(Fig. 1). 그리고 구축 모델에 따라 클라우드 플랫폼 자체는 퍼블릭 또는 전용으로 분류될 수 있다(Mell and Grance, 2011).
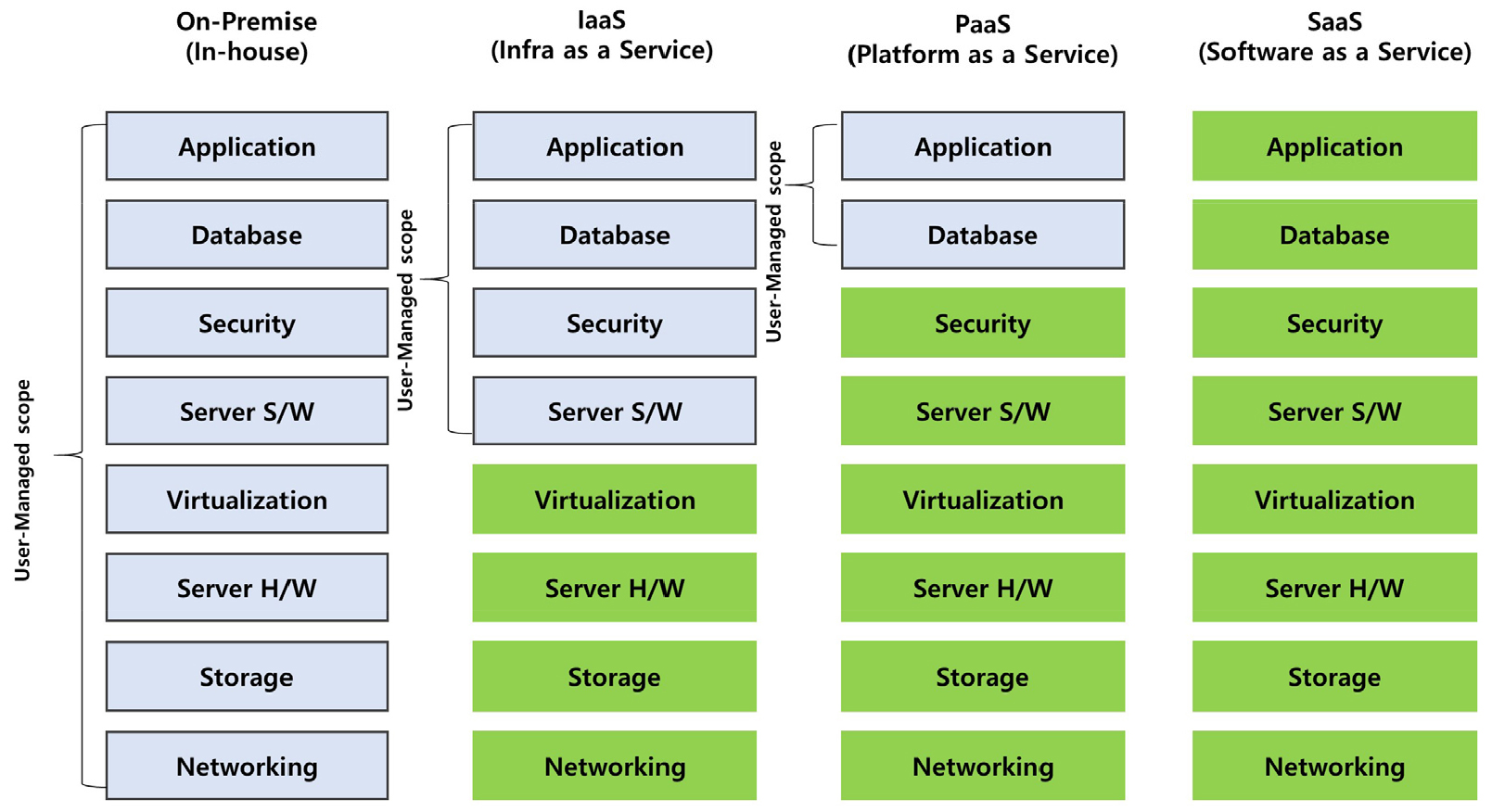
클라우드 서비스타입은 아래와 같은 방식들을 통해 해양수치모델에 적용 가능하다. 가장 일반적인 방법은 수치모델을 수행하기 위한 인프라 환경인 서버와 저장공간 및 네트워크와 같은 인프라자원을 제공받는 방식인 인프라서비스를 이용하는 것이다. 본 연구도 클라우드 인프라 서비스를 통해 인프라를 제공받은 후 수치모델을 수행하기 위해 필요한 컴파일러 및 MPI 등과 같은 기본 소프트웨어를 설치한 후 수치모델을 구성하여 수행하였다. 또 다른 방식은 필요한 인프라와 더불어 컨테이너 엔진과 같은 플랫폼 소프트웨어가 함께 설치되어 있는 형태로 제공을 받는 플랫폼서비스를 적용하는 것이다. 컨테이너 엔진이 설치된 클라우드 서비스에 ROMS와 같은 수치모델과 더불어 이를 수행하기 위한 모든 소프트웨어가 포함된 컨테이너 이미지를 다운로드 받아서 수행하는 경우가 대표적인 예이다(Jung et al., 2021; Cheng et al., 2022). 그리고 필요한 수치모델은 클라우드 환경에 이미 구성되어 있고 특정 영역과 다양한 변수 값을 연구자들이 설정한 후 모델수행 및 결과만을 제공받을 수 있는 형태가 소프트웨어 서비스의 모습이다.
아마존, 마이크로소프트, 구글, IBM 등 IT기업들이 각각 AWS, Azure, GCP, Bluemix 등 퍼블릭 클라우드와 국내에서도 일부 회사가 상용서비스를 제공하며(Gartner, 2018), 전용 클라우드는 내부 사용자 및 목적을 위해 조직에 의해 주로 구축이 된다. 본 연구에서는 해양 수치모델을 실행하기 위한 물리자원인 서버 자원을 가상화 하여 제공하는 인프라 서비스 형태의 퍼블릭 클라우드 서비스를 사용했다. 가상화는 인프라 서비스를 제공할 때 필요한 핵심 기술인데 가상화를 통해 물리적 서버, 스토리지 및 네트워크 자원을 논리적으로 분할하여 사용자에게 할당하고 작업이 완료되면 논리적으로 반환할 수 있다. 본 연구에서는 제공받은 가상화된 서버자원에 수치모델을 수행하기 위해 필요한 MPI와 같은 소프트웨어 환경을 구성하고 해양수치모델을 구축하여 본 연구에 활용하였다.
2.2 상업용 클라우드 서비스
퍼블릭 클라우드 서비스를 활용하는 연구는 점차 증가하고 있으며 수치모델에 적합한 HPC 서비스를 제공하는 클라우드 서비스도 점차 늘어나고 있다. 아마존의 AWS, 마이크로소프트의 Azure, IBM의 Bluemix, 구글의 GCP 등 글로벌 시장의 주요 상업용 퍼블릭 클라우드 서비스는 수많은 자료 센터를 보유하고 있으며 다양한 국가에서 많은 서비스를 제공하고 있다(Gartner, 2018). 또한, 상업용 클라우드를 사용하여 지구 과학 관련 정보를 저장하고 처리하는 기관의 수도 증가하고 있다(Chen et al., 2017). 뿐만 아니라 대용량의 위성영상 자료를 저장하거나 수치모델에서 생산된 자료를 저장하는데도 이용되고 있다. HPC를 보다 손쉽게 사용하기 위해서 수치모델의 병렬처리를 위한 MPI 소프트웨어 및 해양모델이 통합되어 하나의 패키징화 되고 여러 클라우드 서비스에 배포가 가능한 형태인 컨테이너(Container)에 관한 연구도 진행되고 있다(Jung et al., 2021).
본 연구에서는 상용 클라우드에서 제공하는 가상화 기반의 고속 네트워크와 메모리로 구성된 가상서버를 이용하여 해양 수치모델을 위한 환경을 구축하고 수치모델을 실행하여 다양한 클러스터 구성, 서버 간 통신 및 I/O의 성능을 분석하였다.
상용 클라우드에서 제공하는 다양한 서버 리소스는 연구 목적에 따라 결합하여 사용할 수 있다. 딥러닝 및 빅데이터 처리에 널리 사용되는 GPU 장착 인스턴스는 클라우드 컴퓨팅에서도 사용할 수 있으며 고가의 IT자원은 사용량에 따라 합리적인 가격으로 사용할 수 있다. 퍼블릭 클라우드 서비스의 가격은 자료 센터 및 리소스 유형에 따라 다르며, 사용자와 서버 간의 거리에 관계없이 가장 경제적인 서버를 선택할 수 있다. 가령 고정형 대신 임시형 인스턴스 유형 리소스(AWS, 2018; google, 2019)를 사용하는 경우, 더 낮은 비용으로 IT 리소스를 사용할 수 있다. 본 연구에서는 상대적으로 가격이 저렴한 오레곤 지역의 자료 센터와 서비스를 선택하였다.
대규모 해양수치모델링에서는 고속 프로세서, 고대역폭 메모리 및 높은 네트워크 처리량이 매우 중요하며 본 연구에서는 수치모델링 실험을 위해 64비트 리눅스를 사용하는 최근 서버를 선택했다. 고성능 가상화 서버는 상용 클라우드가 10 Gbps 이상의 높은 대역폭을 제공하며(Table 1; AWS, 2022), 메시지 크기가 32 바이트 미만인 경우 대기 시간 값이 36~42 µs 사이이기 때문에 512 core 수준의 MPI를 사용하는 수치모델에 적합하다(Table 2). 실제 인피니밴드 스위치를 사용하는 네트워크의 latency는 이 값들 보다 빠른 10 µs 이하이긴 하나, 실제 수치모델의 경우 네트워크의 latency 뿐만 아니라 메모리속도, CPU등에 복합적으로 영향을 받는다.
Table 1.
Overview of purpose, specifications, and price of AWS instance types (us-west-2, Oregon)
Table 2.
Latency of cloud HPC clusters according to message size
| Message size | 1 byte | 2 bytes | 4 bytes | 8 bytes | 16 bytes | 32 bytes |
| Latency (µs) | 36.2 | 38.8 | 36.6 | 35.6 | 40.7 | 36 |
뿐만 아니라 퍼블릭 클라우드 서비스와 같은 가상화 컴퓨팅 환경에서 대규모 모델링을 위한 환경구축 시 가상서버 템플릿 복사를 통해서 모델링 서버를 준비하는 시간을 최소화할 수 있다. 모델링을 위해 한번 구축된 가상서버의 구성상태를 이미지화 해 두면(AWS, 2017), 필요시 언제라도 동일한 이미지의 가상서버를 동시에 여러 대를 만들 수 있기 때문에 퍼블릭 클라우드 서비스와 같은 가상화 컴퓨팅 환경에서 대규모 모델을 위한 가상서버 템플릿을 통한 수치모델 환경 구축을 통해서 모델링 준비 시간을 최소화할 수 있으며 동일한 모델의 재현성도 높일 수 있다. 본 연구에서도 여러 개의 계산용 노드를 준비하는데 가상서버 템플릿을 활용하여 구성하였다.
3. 클라우드 기반의 수치모델 처리성능 분석
상용 클라우드 환경에서 해양 수치모델링의 처리성능 분석은 해당 수치모델의 수행시간 예측과 더불어 비용을 최소화함에 있어 중요하다. CPU와 메모리는 수치모델의 처리성능을 결정하는 핵심적인 중요한 구성 요소이다. 일반적인 물리서버를 사용하는 전산실의 클러스터를 이용하는 경우에는 물리적인 CPU와 메모리가 고정되어 공급이 되었으나, 클라우드 환경에서는 다양한 리소스 유형을 가상화된 상태에서 네트워크를 통해서 공급받는다. 고정된 물리적 인프라보다 자원구성의 변경이 손쉽기 때문에 사전에 파일럿 형태로 모델링 환경을 구성하고 예상 모델링의 성능을 계산한 후, 대규모 모델링을 위한 리소스를 선택하고 모델링을 수행하는 것이 보다 경제적이라고 할 수 있다. 이러한 처리성능 분석을 위해서 본 연구에서는 표준 성능분석 소프트웨어와 해양 수치모델 실험을 동시에 수행하였다.
3.1 수치모델 성능분석용 소프트웨어
병렬처리의 성능을 분석하기 위해서 사용되는 소프트웨어중에 하나인 High Performance Linpack (HPL)은 고성능 컴퓨팅 클러스터의 성능을 평가하는 데 유용한 도구이다(Rajan et al., 2012; HPL, 2016). 일반적인 해양수치모델들은 MPI 클러스터와 같은 분산 메모리 컴퓨터에서 랜덤 고밀도 선형 시스템을 이중 정밀도(64비트) 산술로 해결하는 벤치마킹 소프트웨어 패키지와 유사한 구조로 동작한다. 따라서, 클러스터의 일반적인 표준성능 측정을 위해서 HPL을 사용하여 성능 테스트를 진행하였으며, 이와 더불어 실제 해양연구에 활용하는 해양 수치모델의 특성 또한 중요하기 때문에 해양수치모델의 성능 측정을 하기 위해서 해양연구에서 많이 사용하는 ROMS의 처리성능과 비교하였다. 해양수치모델을 수행하기 위한 클러스터의 표준 성능은 해당클러스터의 처리능력을 나타나는 초당 부동소수점 처리 단위인 Floating point operations per second (Flops)로 평가하였다.
해양 수치모델링의 경우 병렬 처리를 위한 여러 서버들 간의 통신규격인 MPI 환경에서 동작하며 격자별로 계산되는 여러 변수를 처리하기 위해서 큰 메모리의 I/O를 요구하기 때문에 메모리 대역폭은 계산 속도를 결정하는 중요한 요소 중에 하나이다. 본 연구에서는 HPC용 STREAM 벤치마크 소프트웨어를 사용하여 가상화된 컴퓨팅 환경에서 메모리의 대역폭을 평가했다(McCalpin et al., 1995; 2017). 메모리 대역폭은 가상화 환경의 CPU 유형 및 인스턴스 유형에 따라 달라지는데 메모리 대역폭은 MPI와 병렬로 각각 단일 노드와 다중 노드를 사용하여 측정되었다. 메모리 지연 시간은 메모리 I/O 성능에도 중요한 요소가 될 수 있으며 메모리 I/O 성능 분석을 위해 Intel 메모리 지연 시간 검사 도구를 사용하여 서버의 메모리 지연 시간을 측정하였다(Intel, 2013; 2018). 대기 시간과 캐시 계층을 분석하여 총 메모리 I/O 성능을 평가하였다.
3.2 해양수치모델
본 연구에 사용된 해양수치모델인 ROMS는 수직적으로는 지형 추종, 수평적으로는 곡선 좌표를 가진 자유 표면 해양모델이다. 모델은 또한 유체 정역학적, 자유 표면 원시 방정식을 유한차분법을 통해 해결한다(Shchepetkin and McWilliams, 2005). 3차 상류 이류 체계와 K-프로파일 매개 변수화 체계(Large et al., 1994)는 각각 수평 이류 및 수직 혼합 재현에 사용된다. 많은 해양 과학자들은 그들의 연구 목적에 따라 다양한 방법으로 ROMS를 사용한다. ROMS는 다양한 물리적 및 수치 옵션을 활성화하기 위해 C 전처리를 사용하여 F90/F95로 작성된 현대적이고 간편한 모듈형 코드로 구성된다. 또한, 여러 개의 메시지 전달 프로토콜을 쉽게 사용할 수 있는 일반적인 분산 메모리 인터페이스를 가지고 있다. 현재 노드 간 자료 교환은 MPI를 사용하여 이루어진다. 뿐만 아니라 MPI2와 대칭 계층형 메모리와 같은 다른 프로토콜들 또한 손쉽게 사용될 수 있다. 모델의 전체 입출력 자료 구조는 Network Common Data Form (NetCDF)을 통해 이루어진다(ROMS, 2015).
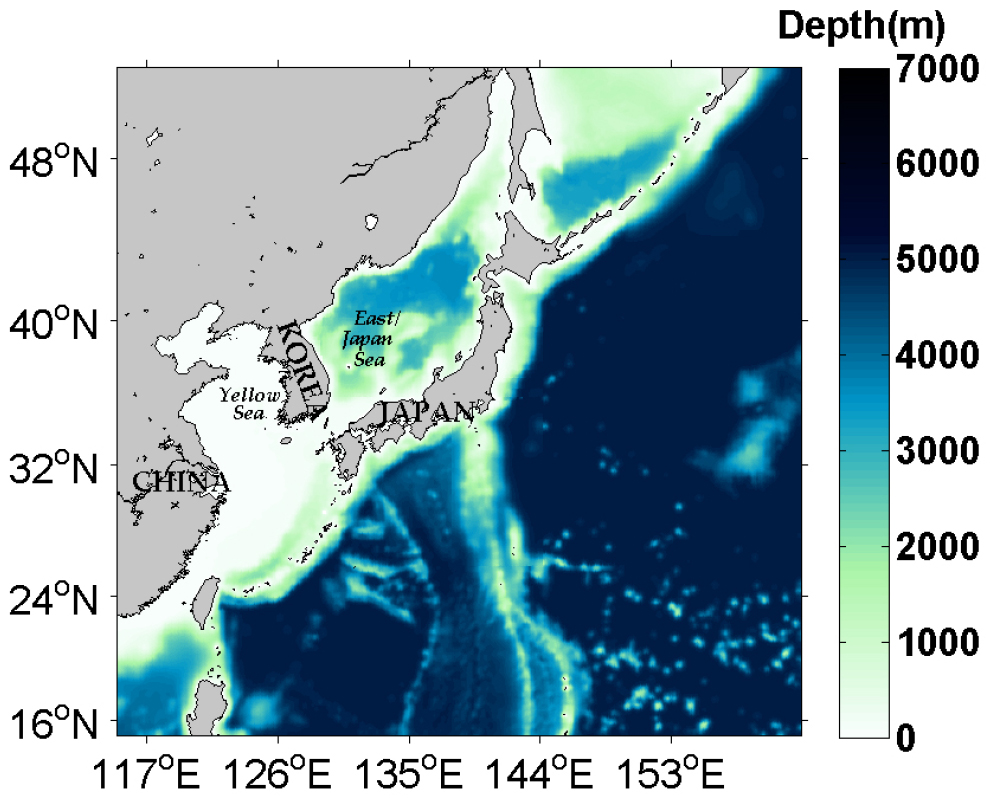
본 연구에서 사용된 모델 영역은, 동서 방향으로 115°E에서 162°E이고 남북 방향으로 15°N에서 52°N이며, 황해, 동중국해, 동/일본해를 포함한다(Fig. 2). 1/10° 수평 격자 해상도와 수직적으로 40개 층으로 구성되었다. 모델의 수심 자료는 Earth topography five minute grid (ETOPO5)를 기반으로 한다(Amante and Eakins, 2009). 초기 온도와 염분은 National Oceanographic Data Center의 World Ocean Atlas 2009 (WOA09)에서 얻었다(Antonov et al., 2010; Locarnini et al., 2010). 측면 개방 경계의 경우, 2010년 Simple Ocean Data Assimilation (SODA; Carton and Giese, 2008)의 월 평균 온도, 염도 및 속도가 적용되었다. 하루 평균 바람, 일사량, 대기 온도, 해수면 압력, 강수량 및 상대 습도를 포함하는 표면 강제력은 2010년 European Centre for Medium-Range Weather Forecasts (ECMWF)의 ERA-interim 자료에서 도출되었다(Dee et al., 2011). 이러한 자료는 bulk formula로 표면 열 유량을 계산하기 위해 적용되었으며(Fairall et al., 1996) TPXO7 모델로부터 획득한 10개 분조를 조석 강제력으로 개방 경계를 통해 입력하였다(Egbert and Erofeeva, 2002). 양자강, 황하 및 한강을 포함한 12개 강의 담수 배출량도 모델에 적용하였다(Vörösmarty et al., 1996; Wang et al., 2008). 모델 구성에 대한 자세한 내용은 Seo et al.(2014)에 소개되어 있다.
4. 수치모델 성능 결과
4.1 표준 벤치마크 성능
상용 클라우드 서비스 회사나 연구기관들은 내부 및 외부 사용자에게 여러가지 형태의 CPU로 구성된 서버 자원을 제공한다. 그리고 이러한 다양한 서버자원을 활용하여 여러가지 종류의 클러스터를 구성하고 수치실험을 수행할 수 있다. 우선, CPU 유형별로 크게 5개의 클러스터를 구성하였고 해당 클러스터에서 측정된 HPL의 성능을 살펴보았다(Fig. 3). 모든 클러스터의 성능은 코어 수에 따라 선형적으로 증가하였고, 증가율은 클러스터를 구성하는 CPU의 성능에 따라 조금씩 다르게 나타났다. 캐시 메모리가 1 MB인 CPU로 구성된 클러스터 C와 D의 성능은 빠르게 증가하는 반면, 캐시 메모리가 256 KB로 구성된 클러스터 A, B, E의 성능은 느리게 증가하였다. 이러한 결과는 클러스터의 성능이 CPU 상세 캐시 구조에 따라 다르다는 것을 보여준다(Table 3). 이는 수치모델용 클러스터의 서버 리소스 유형에 따라 H/W 효율성이 다르기 때문에 수치해양모델을 실행하기 전에 모델링 수행에 적합한 자원 유형을 결정하고 대규모 모델링을 수행하는 것이 전체적인 모델링 수행 시간을 줄이는데 도움이 될 수 있다는 것을 의미한다.
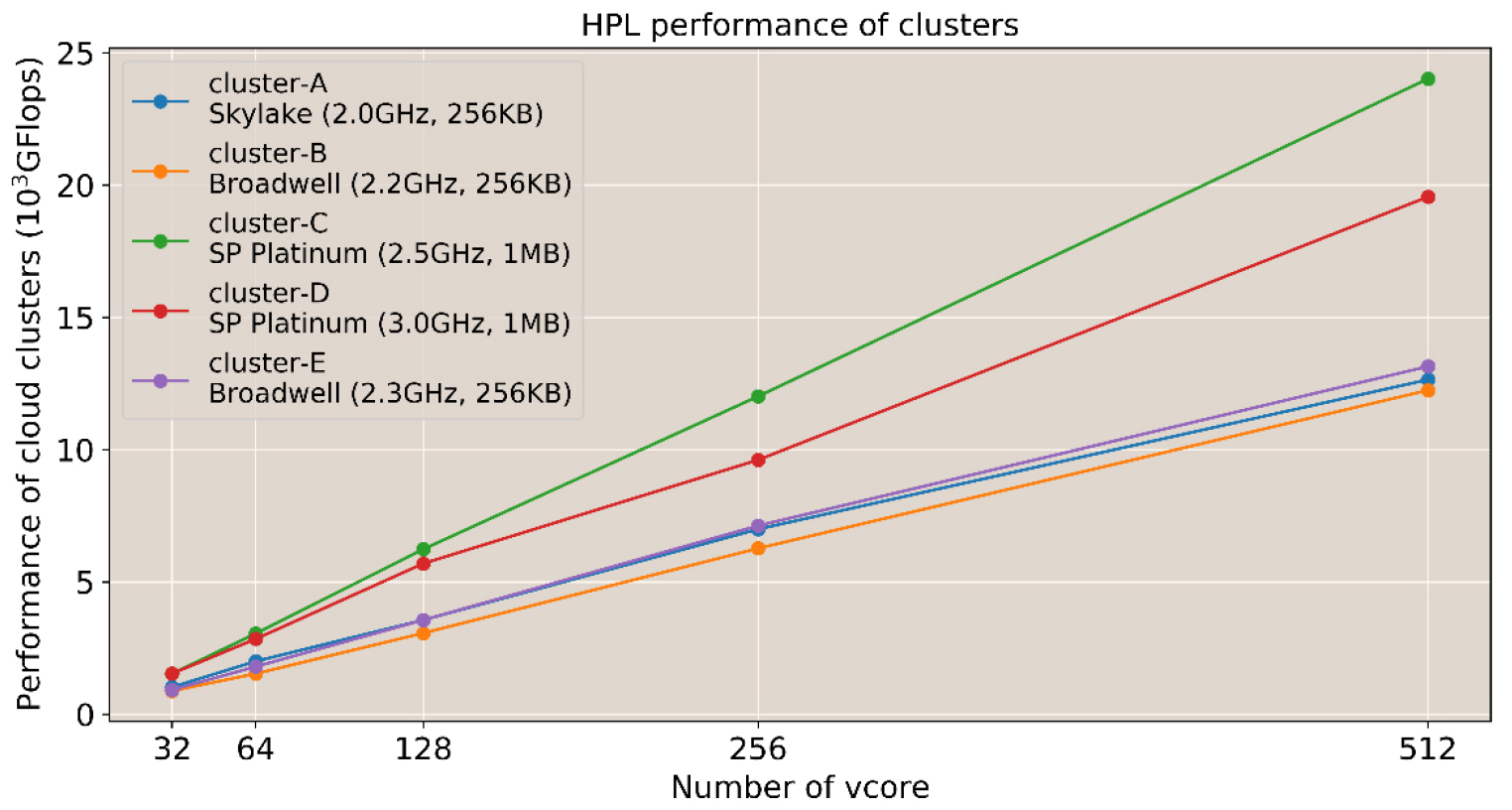
Table 3.
CPU specification of cloud HPC Clusters
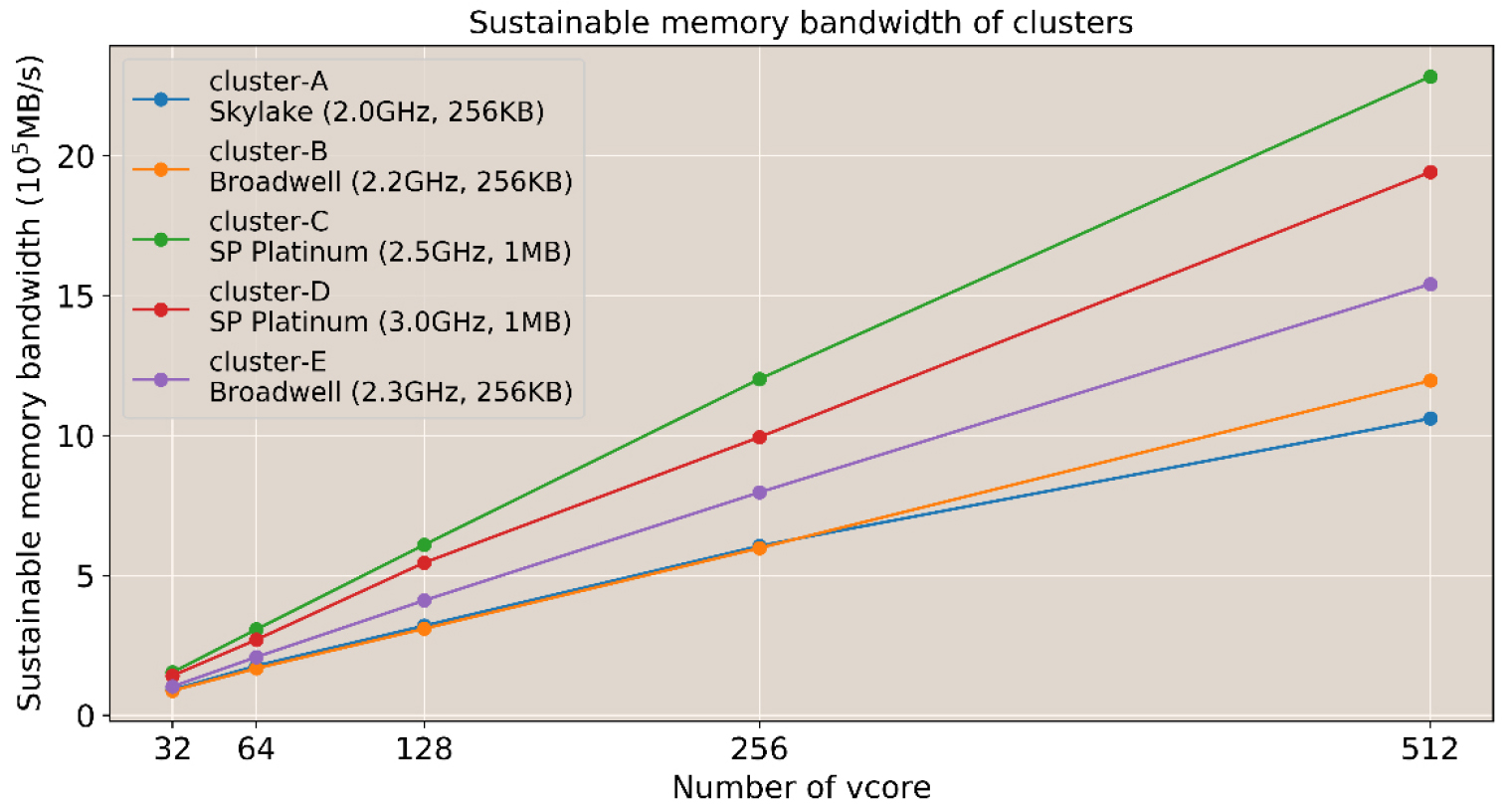
수치모델에서는 CPU와 더불어 메모리의 성능이 매우 중요하다. 특히 노드 별로 분산처리 하는 경우 분산환경에서 수치모델이 수행되는 메모리의 성능을 비교 분석하는 것이 필요하다. 클러스터의 메모리 성능측정 도구인 STREAM 벤치마크 결과를 통해, 전체적인 처리 성능은 노드 수에 따라 증가하지만 노드당 대역폭은 감소한다는 것을 알 수 있었다(Fig. 4). 이 성능 결과는 노드의 메모리 성능이 원격 노드 I/O의 증가에 따라 일정 부분이 감소됨을 시사한다. 코어에 따른 메모리 대역폭 증가율은 클러스터마다 다르게 나타나는데 Fig. 4와 같이 클러스터 C와 D의 처리성능이 다른 클러스터들 보다 더 뛰어났다. 이 메모리 대역폭은 대용량 메모리 I/O를 사용하는 MPI 기반 수치모델의 성능을 결정하는 데 중요한 역할을 할 수 있다.
4.2 해양수치모델 성능
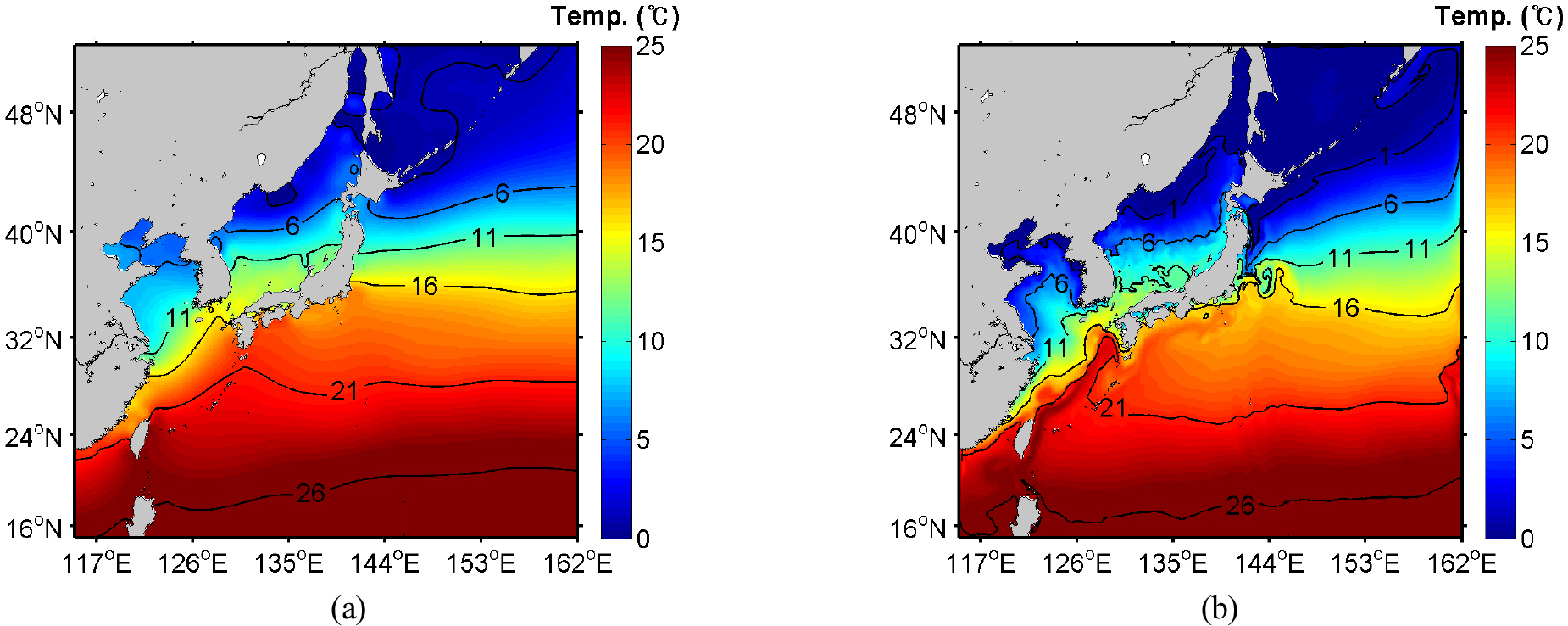
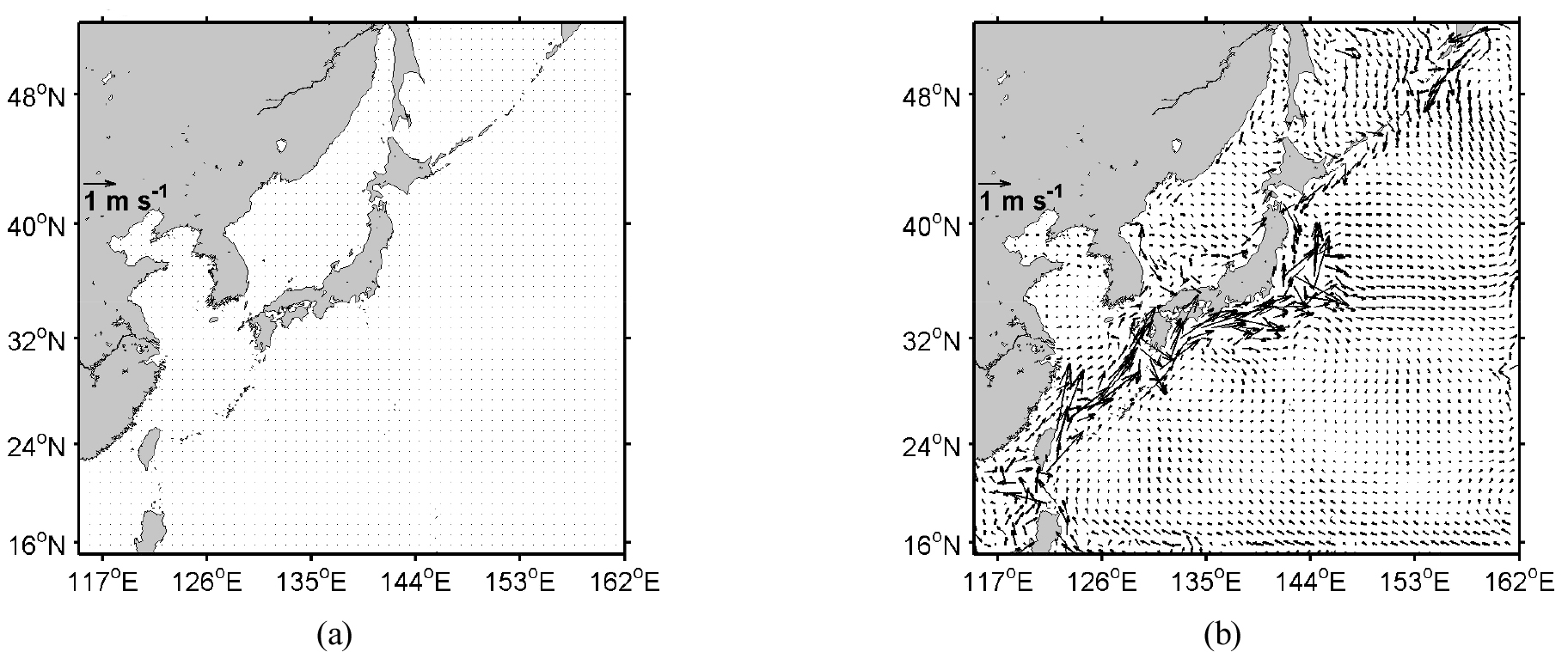
Fig. 5와 Fig. 6은 각각 2010년 1월 1일부터 ROMS 모델을 30일간 실행 후 재현된 해수면 온도(SST)와 표면 속도를 보여준다. 따뜻한 물과 빠른 속도가 특징인 쿠로시오 해류는 오키나와 해곡과 일본 동해안을 따라 잘 재현되었다. 오호츠크 해, 동해 북부 해역, 황해 연안에는 대기 냉각과 수직 혼합의 결과로 차가운 물이 나타났다(Seo et al., 2014). 코어에 따라 수행된 물리 서버와 클라우드 가상서버에서의 수행 결과를 비교 분석하면 SST의 경우 평균 제곱근 편차(RMSE)는 0.0057~0.0097℃이고, 속도의 u-성분 및 v-성분의 RMSE는 약 0.0005 ms-1이다. 이는 상용 클라우드 시스템과 물리 서버의 수행 결과 차이가 거의 없으며 계산 재현성이 우수하다는 것을 의미한다.
5. 클라우드 환경기반의 수치모델 성능분석
5.1 HW 자원 구성에 따른 성능분석
현재 상용 클라우드 회사나 기관의 전산실에서는 일반적으로 수치모델 클러스터를 구성하기 위해서 Intel Xeon CPU를 사용한다(Table 3). 최근 인텔 Xeon 프로세서(SP) 제품군은 이전 세대 제품군보다 더 많은 기능을 갖추고 있다(Intel, 2017). 특히 캐시 구조는 이전 세대와 확연히 다르다. 브로드웰과 하스웰과 같은 CPU에서 중간 캐시 메모리인 Mid-Level-Cache (MLC)는 코어당 256 KB였고, 하위 캐시 메모리인 Last-Level-Cache (LLC)는 코어당 최대 2.5 MB였다. Fig. 7은 각 클러스터의 리소스 유형 및 격자 크기에 따른 ROMS 실행 시간을 보여준다. 모델의 수행시간은 리소스 유형 및 격자 크기에 따라 다르게 나타났다. 이 결과는 실행 성능 평가함에 있어 시스템의 자원 구성도 같이 비교검토 되어야 하며, 동시에 자원의 구성변경이 가능한 클라우드 환경에서는 이러한 점을 고려해서 수치모델용 클러스터를 구성해야 한다는 점을 제시한다.
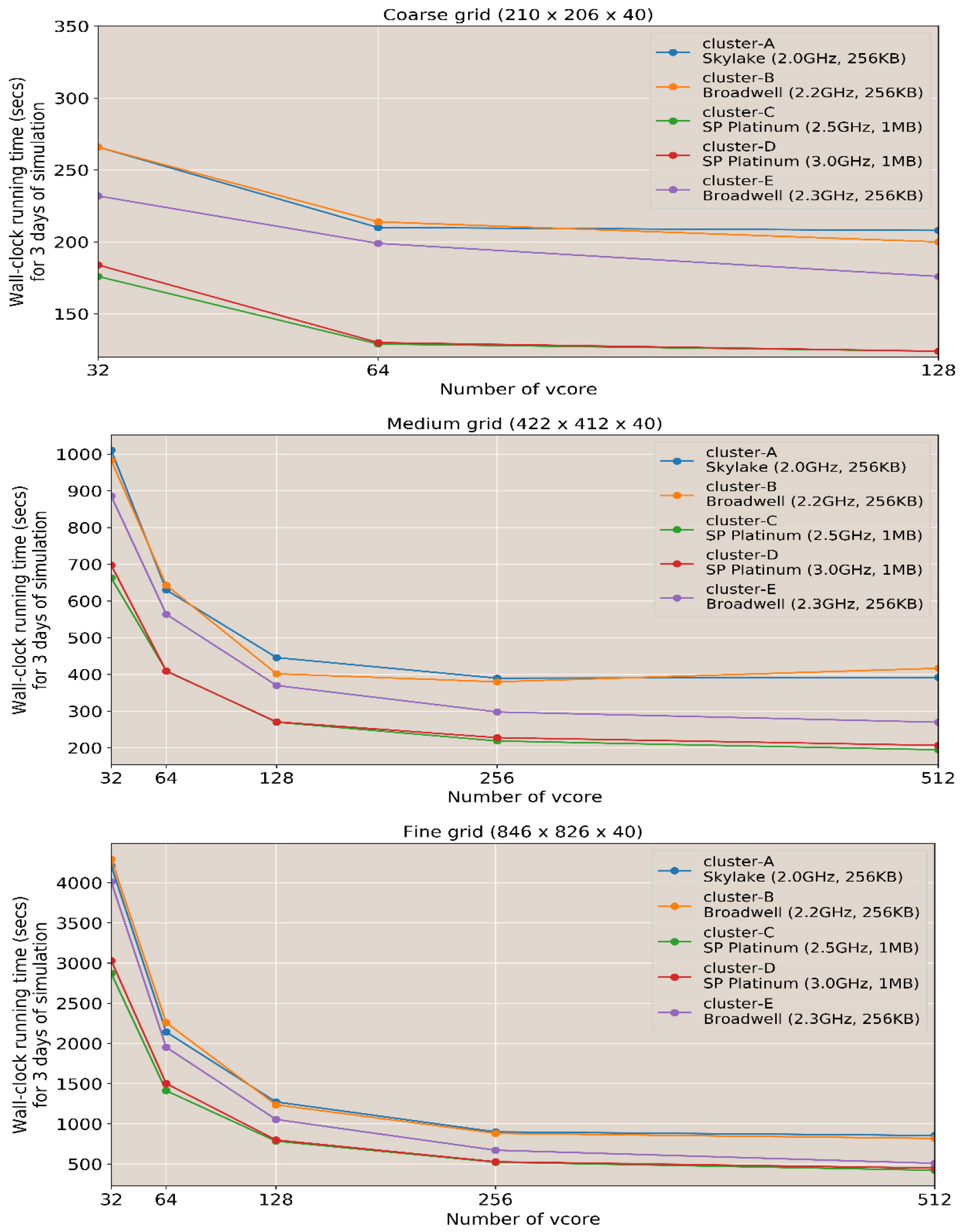
연구 결과에서 알 수 있듯이 ROMS의 실행 시간은 캐시 용량과 계층에 따라 달라질 수 있다. 클러스터 C와 D는 격자 크기에 상관없이 빠른 실행 시간을 보여주었다(Fig. 7). 이는 클러스터 C와 D의 MLC가 클수록 메모리와 CPU 간의 지연 시간이 줄어들어 수치모델을 수행하는데 좀 더 나은 성능을 낼 수 있다는 것을 의미한다. 또한 ROMS의 실행 성능은 HPL과 유사한 패턴을 보인다. 고성능 캐시 메모리가 장착된 CPU는 Fig. 4와 같이 HPL에 대해 더 나은 성능을 보여주었다. CPU 클럭은 빠르지만 ROMS의 성능은 CPU와 메모리 사이의 지연 시간이 긴 클러스터에서 상대적으로 낮게 나타났다. 이는 대용량 메모리 로드에서 메모리 I/O의 지연 시간이 길어질 수 있기 때문이다. 가상화된 서버에서 ROMS의 성능은 확실히 캐시 계층에 의해 달라지는데, 이는 CPU와 메모리 간의 지연 시간을 줄여주었다.
5.2 격자 크기에 따른 성능분석
우리는 실험 결과를 계산 격자의 수인 자유도(DOF) 크기에 따라 세 가지로 나누어 CPU 리소스 유형과 메모리 I/O에 따라 실행 시간을 평가했다(Table 4). 실행 시간은 CPU 리소스 유형에 따라 다르지만 전체적으로 클러스터의 성능은 캐시의 성능과 코어수에 따라 좌우된다. 코어 수가 증가함에 따라 저해상도 격자의 실행 시간이 감소하며 실행시간이 최대로 감소하는 시점, 임계점은 CPU 리소스 유형에 관계없이 약 128개의 코어에서 나타났다. 절대적인 실행 시간은 코어 수의 증가에 따라 감소하는데 격자 크기별로 차이를 보였다. 중간 해상도의 경우 약 256개의 코어에서 임계점이 나타나며, 고해상도 격자의 경우 512개 이상까지 실행시간이 감소한다.
Table 4.
Numerical Ocean Model Grid-Size Type
| Resolution of grid | Coarse | Medium | Fine |
| Dimensions of grid | 210×206×40 | 422×412×40 | 846×826×40 |
| Degree Of Freedom (DOF) | 1,730,400 | 6,954,560 | 27,951,840 |
32개의 가상화된 CPU 코어인 virtual core (vcore)를 기준 효율로 가정하여 상대적인 효율성을 계산했다. 코어 수에 따른 효율은 격자 크기에 상관없이 빠르게 감소하였다(Fig. 8). 수치모델을 수행하는 코어 수가 증가하면 모든 격자에서 효율이 감소하며 효율은 계산량이 많은 고해상도 격자보다 계산량이 작은 저해상도 격자에서 더 빠르게 감소하였다. 이를 통해 해상도가 높고 계산해야 할 격자가 많을수록 CPU의 효율성은 상대적으로 높다고 할 수 있다.
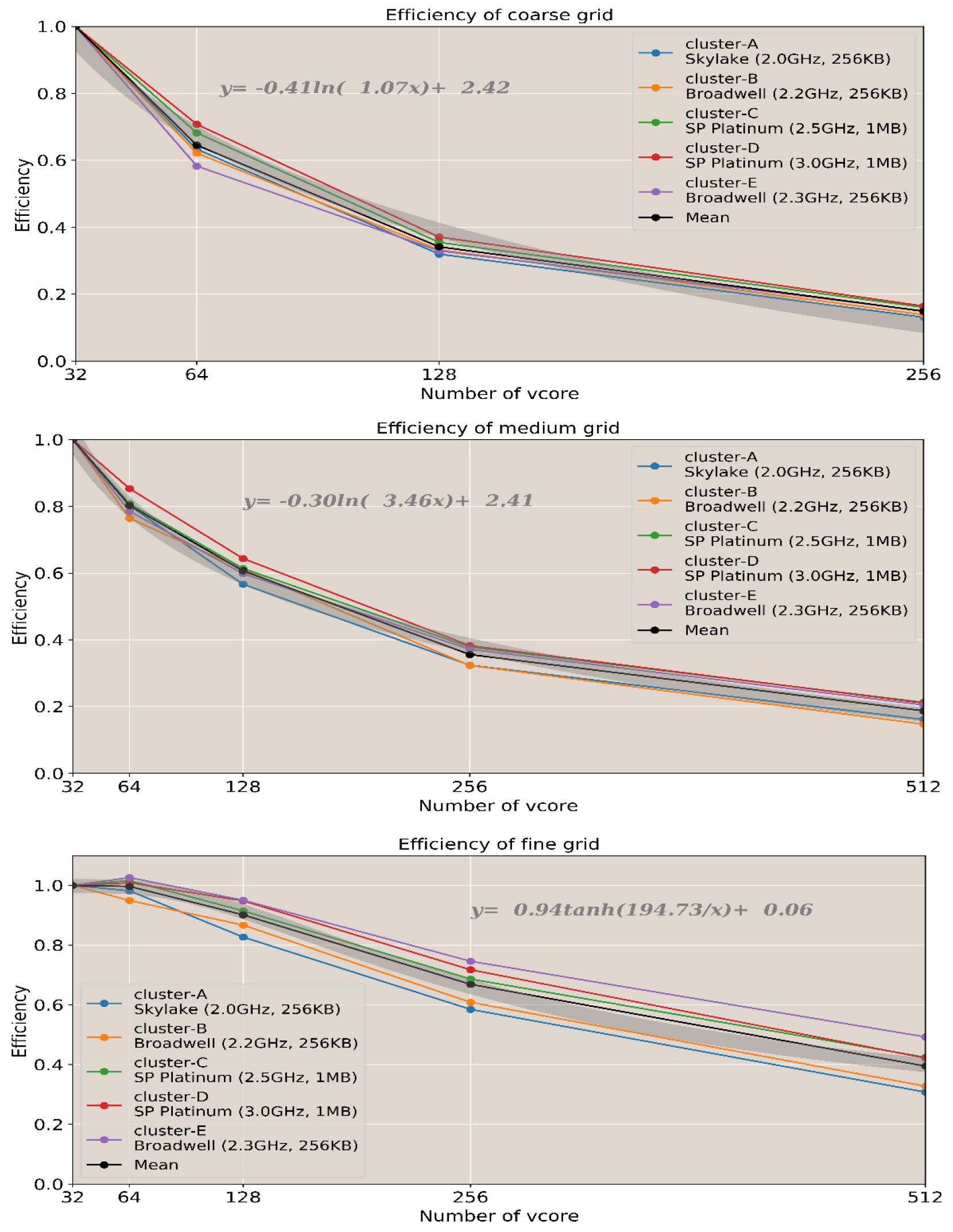
Fig. 8에서 볼 수 있듯이 수치모델 실험 시 코어 수를 32개에서 128개로 4배를 증가시키면 해상도가 낮은 모델(격자 수: 1,730,400개)에서는 효율이 약 0.35로 감소하지만 해상도가 높은 모델(격자 수: 27,951,840개)에서는 0.82–0.95로 상대적으로 작게 감소한다. 그래서 본 연구에서 실험된 저해상도 격자의 경우 코어가 256개에서 최저 효율로 떨어진다. 하지만 고해상도 격자의 경우 512개의 코어까지 증가시켜도 최저효율로 떨어지지 않았기 때문에 코어 수를 증가시키면 수행시간을 줄일 수 있다는 것을 의미한다.
5.3 ROMS 수평격자 해상도에 따른 자원 최적화 방안
본 연구에서는 클라우드 환경에서 구축된 수치모델용 클러스터에서 ROMS 모델 수행 시에 최적의 자원을 할당하기 위하여 해상도 별로 수행되는 ROMS의 수행시간과 각각의 클러스터의 성능측정자료를 활용하여 효율성을 기준으로 최적의 자원할당 방안을 도출하였다. Fig. 7에서 보는 바와 같이 coarse 격자의 경우 67코어 수준의 자원을 투입할 경우 효율성이 66% 정도 달성되었다. 그리고 medium 격자의 경우는 100 코어, fine 격자의 경우, 258 코어로 추정 된다. 효율성을 33%로 하였을 때 coarse 격자의 경우 151 코어, medium 격자의 경우 295 코어, fine 격자의 경우 550 코어로 추정이 된다. 하지만 투입되는 자원에 비해서 Fig. 7에서와 같이 수행시간의 절대 단축 시간을 고려할 때 66%의 효율을 기준으로 자원을 투입하는 것이 적합하다. 일반적으로 32–36 CPU 코어 기준으로 한 대의 서버가 구성되기 때문에 coarse 격자의 경우 2대의 서버로 구성된 클러스터를 할당하는 것이 가격과 성능면에서 적절하며, medium 격자의 경우 128 코어로 구성된 4대의 서버자원으로 구성된 클러스터가 적합하다. 그리고 fine 격자의 경우 8대의 서버자원으로 구성된 256 코어 수준의 클러스터를 구성하였을 때 투입되는 자원의 가격성능비가 최적화 된다고 볼 수 있다.
해당 클러스터를 초당 연산처리 능력인 GFLOPS 기준으로 서버자원을 구축한다고 하면 coarse한 격자를 처리하는 데 필요한 클러스터는 약 2.5×103GFLOPS의 처리성능을 지닌 클러스터의 구성이 필요하며, medium의 경우 약 5.0×103GFLOPS의 처리성능, 그리고 fine 격자는 약 10.0×103GFLOPS의 처리성능을 가진 클러스터를 확보하면 적합할 것이다.
Table 5는 Public Cloud에서 ROMS 모델의 수행 시 해상도별로 66% 효율을 기준으로 적절한 자원의 양, FLOPS 기준의 처리성능을 표시하였다. 인프라 자원들의 성능과 구성은 지속적으로 바뀌고 있기 때문에 FLOPS를 기준으로 처리성능을 확보하는 것도 필요자원을 산정하는 것도 필요하다.
Table 5.
Numerical Ocean Model Grid-Size Type
6. 결론 및 토론
본 연구에서는 다양한 클라우드 환경에서 해양수치모델을 수행하여 각각의 처리성능을 비교평가하였다. 성능을 보다 객관적으로 평가하기 위해 해양 수치모델뿐만 아니라 STREAM, HPL 등의 벤치마크 소프트웨어를 가상화 서버를 사용하는 클라우드 HPC환경에서 실행하였다. 서로 다른 CPU와 메모리를 가진 다섯 개의 클러스터를 대상으로 각각 세 가지 다른 격자 크기에 대한 해양수치모델 실험을 수행하였다.
CPU와 메인 메모리 사이의 캐시 계층과 용량이 거대한 메모리를 사용하는 해양수치모델의 성능에 중요한 역할을 한다는 것을 확인하였다. 클러스터의 성능은 메모리 캐시 메모리인 MLC에 크게 영향을 받는다. MLC 용량이 작은(256 KB) 클러스터는 상대적으로 큰 용량(1 MB)의 클러스터보다 낮은 성능을 보인다. 메모리 지연 시간은 상용 클라우드 HPC 환경에서 실행 성능의 핵심 요소이기도 하다. 상용 클라우드에서 많은 가상 코어 및 이더넷 기반 네트워크로 구성된 클러스터는 해양 수치모델링에서 전체적으로 우수한 성능을 제공하는 것으로 나타났다. 해양수치모델은 다차원 자료를 대용량 배열 형태로 처리하는 경우가 많으며 병렬처리를 위해서 서버 간 통신량이 증가한다. 클라우드 기반의 수치모델 클러스터 환경에서 성능개선을 얻을 수 있는 캐시메모리의 효과가 더욱 컸다. 클라우드 환경에서는 사용자가 다양한 서버자원을 선택하고 구성할 수 있기 때문에 이더넷 기반의 클러스터 구성할 때 이러한 캐시메모리 효과를 고려하여 구성하여야 한다.
해양수치모델의 격자에 따른 처리성능을 코어 개수에 따른 격자 별 수행 시간을 통해서 살펴보았다. 코어 수 증가에 따른 처리 효율은 격자 해상도가 높은 모델보다 해상도가 낮은 모델에서 더 빠르게 감소한다는 것을 알 수 있었다. 수치모델 실험 시 코어 수를 32개에서 128개로 4배를 증가시키면 효율은 해상도가 낮은 모델에서는 약 0.35로 감소하지만 해상도가 높은 에서는 0.82–0.95로 감소한다. 이러한 점을 고려하여 계산량에 따라 어느정도 CPU자원을 투입할 것인지 판단하여야 한다. 일부 수치모델은 격자 크기와 노드 간의 통신 지연 시간 및 메모리 크기에 따라 그 처리성능이 달라질 수 있고 이러한 제약은 클라우드 컴퓨팅 환경에서 적절한 리소스 선택과 다양한 구성을 통해 해결될 수 있다.
본 연구에서는 ROMS를 이용한 수치실험을 통해 해상도별 효율성을 기준으로 클라우드의 클러스터 환경에서 최적의 자원 필요량을 분석하였다. 수평해상도가 coarse한 1/5° 격자 해상도 경우 효율성이 66% 기준으로 CPU자원이 64 코어 수준일 때 최적이며, 수평해상도가 medium한 1/10° 격자 해상도의 경우 최적의 CPU자원은 128 코어 이며, fine한 1/20° 격자 해상도를 처리하는 경우 256 코어 규모가 최적으로 판단된다.
클라우드 기반의 클러스터의 확장성 고려하여 향후 서버들간의 고속네트워크 장치인 인피니밴드 혹은 옴니패스로 구성되어 있는 전용 클러스터와의 성능 비교를 통해서 클라우드 컴퓨팅 환경에서 구축된 수치모델용 클러스터의 성능이 전용클러스터에 대비하여 유사한 성능을 제공할 수 있는지 비교 검토가 필요하다. 더불어 1024 코어 이상의 CPU자원으로 구성된 대형 클러스터의 성능분석을 통해서 초고해상도 및 전구모델을 수행하는데 있어 클라우드 환경이 적합성과 성능개선방향도 추가 연구가 필요하다.
상용 클라우드 컴퓨팅 환경에서 해양수치모델의 처리성능은 적절한 CPU와 메모리를 선택하고 모델링 환경을 최적화함으로써 달성할 수 있다. 상용 클라우드 컴퓨팅 환경은 대규모 수치모델을 실행하기 위한 비용 효율화 방안 중 하나이며, 클라우드 컴퓨팅의 보안을 향상시키기 위해 다양한 기술과 리소스 구성을 사용할 수 있다. 뿐만 아니라 가상서버의 이미지 복사 및 공유 기술을 사용하여 클라우드 환경에서 해양수치모델의 모델 환경 구성을 빠르게 구현할 수 있다. 이를 통해 다국적 연구를 수행해야 하거나 원격지에서 근무하는 연구원들 간 협업을 보다 쉽게 수행할 수 있을 것으로 판단된다. 이러한 관점에서 클라우드 컴퓨팅은 많은 해양수치모델을 기반으로 하는 연구자들에게 연구에 집중할 수 있는 환경을 제공하고 해양수치모델링 환경을 구축하는데 필요한 리소스 시간과 비용을 최소화하는데 도움을 줄 수 있을 것이다.
본 연구에서는 클라우드 클러스터를 구성하는 CPU 유형 5개에 대한 분석 결과를 제시하였다. 해당 CPU 유형으로 클라우드 기반 클러스터를 구성하였을 때 구현될 수 있는 처리성능치를 FLOPS 성능 값과 클러스터 메모리 성능 값을 제시하였기 때문에 연구자들이 확보하고 있는 물리서버 클러스터의 성능을 보다 정량적으로 비교 평가하는데 활용할 수 있다. 개별 연구실 혹은 연구기관이 소유한 수치모델용 클러스터는 하드웨어 구성과 네트워크 성능, 소프트웨어 구성환경이 다양하기 때문에 개별 성능을 직접 비교하는 것은 현실적으로 어려움이 있다. 그러나 본 연구에서 적용한 HPL 벤치마크 소프트웨어로 측정한 FLOPS 성능 값과 메모리 성능자료를 참고하여 해당 물리 클러스터의 성능을 측정하면 현재 보유한 장비에 대한 대략의 성능치를 확인할 수 있고, 클라우드 기반 클러스터와의 성능 비교가 가능할 것이다. 이미 수치모델용 물리 클러스터를 확보한 경우라면 자원 부족 부분이 발생하거나 단기간에 대규모 수치모델을 수행하여야 할 때 일시적으로 상용이나 공용 클라우드 컴퓨팅 환경을 활용할 수 있을 것이며, 추가적으로 도입해야 할 자원에 대한 용량산정이나 단기간에 별도의 성능테스트 환경 혹은 타 기관과의 협업 환경이 필요한 경우 클라우드 컴퓨팅 환경을 활용함으로써 수치모델링 구축 및 수행에 도움을 줄 수 있을 것이다.
