

1. 서 론
2. 연구 방법
2.1 대상 지역
2.2 자료 수집 및 전처리
2.3 모델 선정 및 알고리즘
2.4 교차검증 및 하이퍼파라미터 튜닝
2.5 변수 중요도(Feature Importance)
2.6 민감도 분석(Sensitivity Analysis)
2.7 모델 성능 평가
3. 결 과
3.1 모델 성능 비교
3.2 변수 중요도
3.3 민감도 분석 결과
3.4 고찰
4. 결 론
1. 서 론
최근 산업화와 개발 압력으로 점·비점오염원이 증가하여 해양 환경의 오염을 악화시키고 있다. 해양 오염을 효율적으로 관리하고 해양환경과 해양생태계를 보전·복원하기 위해서 해양 수질을 지속적으로 모니터링(monitoring)하고 있으며, 수집된 수질 조사 자료(water quality dataset)를 바탕으로 수질평가지수(water quality index, WQI)로 평가한다. WQI는 수질의 시공간 변화를 표현하는 많은 양의 복잡한 자료를 보다 직관적으로 파악하기 쉽게 단위가 없는 정수로 표현하여 여러 국가에서 사용된다. 그러나 WQI를 결정하는 모델(model)은 해역 별 특성과 다양한 요인(해역의 용도, 불충분한 수질 조사, 전문가의 주관 등)에 의해 영향을 받을 수 있다(Uddin et al., 2021). 이러한 이유로 WQI의 불확실성(uncertainty)을 해소하고 수질 조사 항목(water quality parameter)을 간소화하기 위하여 적절한 WQI 예측(prediction) 모델이 요구된다.
해역 별로 상이하게 발생하는 환경 문제(부영양화, 빈산소, 중금속 오염 등)로 수질 조사 항목이 증가하여 WQI를 결정하는 모델이 복잡해지고 비선형성(non-linearity)을 나타낸다. 이에 주성분 분석(principal component analysis, PCA)이나 군집화(clustering)와 같은 수학적인 접근으로 중복되는 특성을 가지는 수질 조사 항목을 제외하거나(Gazzaz et al., 2012; Lee et al., 2014; Tripathi and Singal, 2019), 퍼지 논리(fuzzy logic)와 같은 인공지능(artificial intelligence, AI)을 활용한 WQI (Gharibi et al., 2012) 평가 모델이 개발되고 있다. 또한 AI를 활용하여 WQI를 예측하는 다양한 연구가 시도되고 있다. 과거에는 다양한 기계학습(machine learning, ML) 알고리즘(algorithm) 기반(Asadollah et al., 2021) 또는 인공 신경망(artificial neural network, ANN) 구조의 모델(Gazzaz et al., 2012; Hameed et al., 2017; Kouadri et al., 2021; Khozani et al., 2022)로 WQI를 예측하였다. 진화 알고리즘(evolutionary algorithm)과 같은 유전(genetic) AI 기술을 사용하여 WQI를 예측하거나(Abba et al., 2020), 단일 알고리즘(standalone algorithm)보다 더 복잡한 자료를 훈련(train)하기 위해 복합 알고리즘(hybrid algorithm) 기반의 모델로 예측하기도 하였다(Yaseen et al., 2018; Li et al., 2019; Bui et al., 2020; Abba et al., 2022). 특히, WQI를 점수(score)가 아닌 등급(class)으로 분류(classification)하는 모델도 제시되었는데, Ho et al.(2019)은 의사결정나무(decision tree, DT) 기반의 모델로 WQI 등급을 예측하였고 다양한 수질 인자 조합으로 모델을 평가(test)하여 설명 변수(암모니아성질소, 수소이온농도, 부유물질)를 축소시켰다. Tiyasha et al.(2021)은 ANN과 random forest (RF), DT 모델을 비교하여 심층 학습(deep learning) 방식의 우수함을 제시했다. Prasad et al.(2021)이 제안한 자동화 기계학습(automated machine learning, AutoML) 알고리즘 기반의 모델은 기존 알고리즘(Naïve Bayes, logistic regression, support vector machine, DT, RF)보다 정확하게 WQI 등급을 분류할 수 있다. 국내는 Jang et al.(2016)이 geostationary ocean color imager (GOCI) 위성으로 수집한 반사도(reflectance) 자료를 이용하여 예측한 WQI를 기존 해양환경측정망 WQI값과 비교하여 RF 모델을 가장 정확한 모델로 보고한 바 있다. Jeon et al.(2020)은 광양만의 수질자동측정망 수질 조사 자료와 기존 해양환경측정망의 WQI 등급 자료를 학습하여 WQI 등급을 예측한 결과 알고리즘 중 RF가 가장 높은 분류 성능(performance)을 보였다. 이와 같이 AI는 사전 정보(domain knowledge) 없이 자료의 복잡한 관계를 모델로 정의할 수 있다.
따라서 AI 기반의 모델은 각 수질 조사 인자의 분석 오차(experimental error) 또는 기준값(reference value)과 비교에서 발생할 수 있는 오류, 실무자의 계산 오류, 등급 간의 근소한 점수 차로 인한 통계적 오류를 방지할 수 있다. 더욱이 복잡한 계산을 간소화하여 WQI 평가의 오류를 최소화할 수 있으며 최적 입력 변수(input variable) 만을 추출하기에 기존 방식보다 시간과 조사 비용을 절약할 수 있는 장점도 있다.
현재 해양환경관리법에서 제시하는 WQI 계산은 생태구(ecological region) 별 해양환경기준을 적용하여 여러 수질 항목(저층 용존산소, 표층 용존무기질소, 표층 용존무기인, 표층 식물성 플랑크톤, 투명도) 별 점수를 평가한 후 산출식에 대입하여 계산하고 있다. 그러나, 동일한 해역 내에서 수질 조사 정점과 계절 별 WQI 값이 매년 큰 차이를 보인다. 예를 들면 조사 시기와 조사 정점의 위치가 변화하거나 관리해역의 지리적 범위가 변경될 경우 현재의 WQI는 해당 해역을 대표하는 수질을 평가하는데 한계가 있다. 따라서 각 정점 및 계절 별 WQI를 계산할 때 시공간적으로 적합한 수질 조사 항목과 계산 모델을 고려하여야 정확한 WQI를 계산할 수 있다. 이 연구는 시화호 특별관리해역을 대상으로 축적된 수질 조사 자료를 이용하여 시화호 해역의 상태를 평가할 수 있는 AI 모델을 개발하고 WQI 평가를 시공간적으로 세분화하여 효율적인 수질 관리 방안을 제안하고자 한다.
2. 연구 방법
2.1 대상 지역
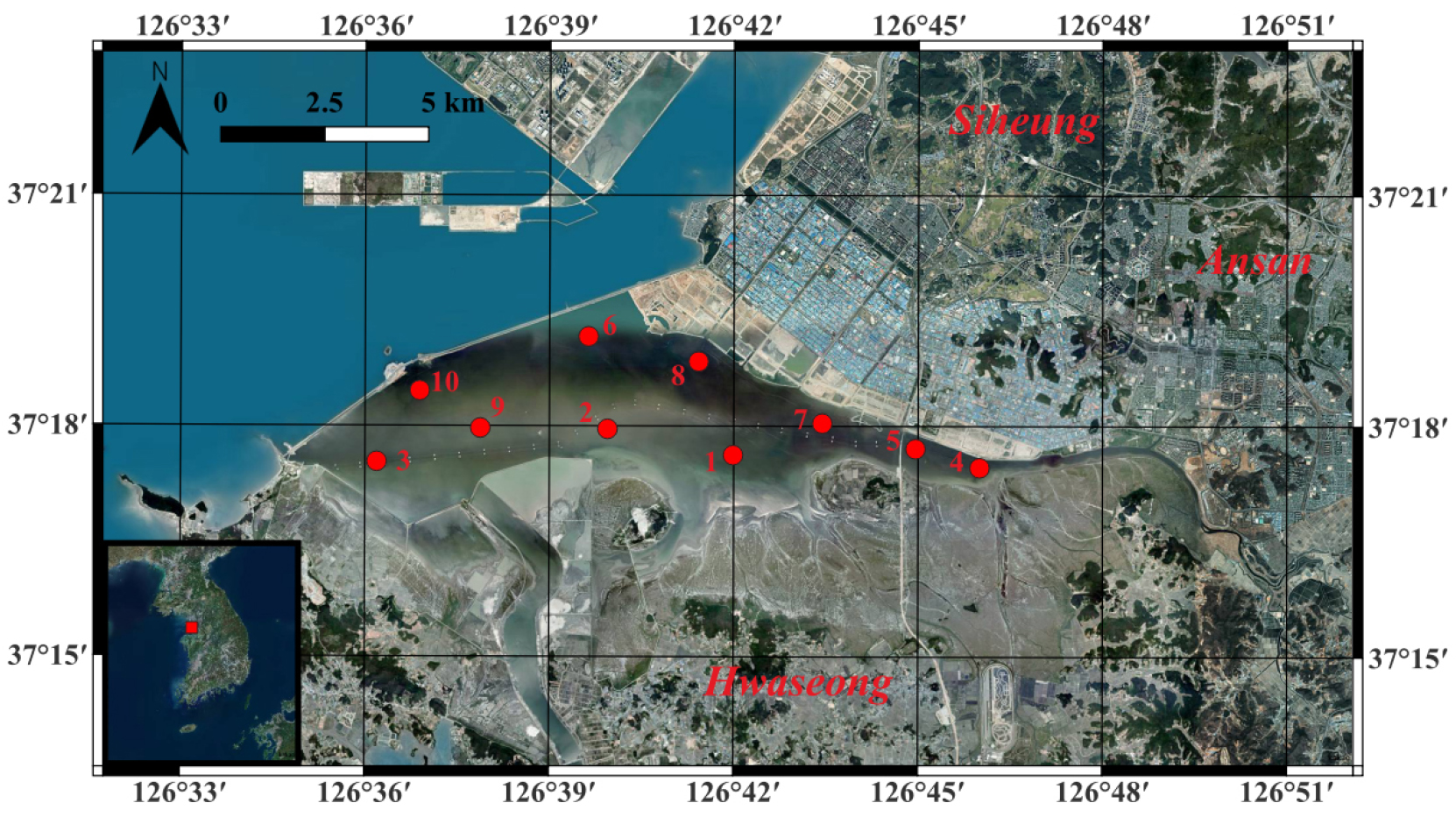
「해양환경관리법」의 환경관리해역 중 특별관리해역에 해당하는 시화호(37°24’56.3”N, 126°95’62.4”E-37°28’40.1”N, 126°56’91.4”E)를 연구 지역으로 했다(Fig. 1). 시화호 특별관리해역은 수평 직선 거리로 약 34 km, 유역 면적은 총 482.9 km2로 해면부 154.2 km2(호수 43.8 km2), 육상부 328.7 km2를 포함하며 시화 방조제를 기준으로 내측과 외측으로 구분된다. 시화호의 북측에는 국가산업단지가 위치하고, 남측에는 간척 농지와 대규모 공공주택 개발 사업이 진행 중으로 육상 기인 오염 물질의 유입이 우려되고 있다. 시화호로 유입되는 하천은 10개, 시화호 주변으로 유입되는 하천은 2개가 있다. 시화호의 최근 5개년(2017-2021) 연 평균 WQI 등급이 3등급(보통)으로 2011년 시화호 조력발전소 가동 이후 해수유통 등의 영향으로 수질이 개선되었다.
2.2 자료 수집 및 전처리
시화호의 해양환경측정망 결과 중 표층(surface)과 저층(bottom)의 수온(temperature), 염분(salinity), 수소이온농도(pH), 용존산소(dissolved oxygen, DO), 화학적산소요구량(chemical oxygen demand, COD), 암모니아성질소(NH3-N), 아질산성질소(NO2-N), 질산성질소(NO3-N), 용존무기질소(dissolved inorganic nitrogen, DIN), 총질소(total nitrogen, TN), 용존무기인(dissolved inorganic phosphorus, DIP), 총인(total phosphorus, TP), 규산규소(SiO2-Si), 부유물질(suspended solids, SS), 엽록소a(chlorophyll a, Chl-a)와 투명도(Secchi disk depth, SD)를 이용하였다(Table 1). 2013년 이전은 분기(2월, 5월, 8월, 11월) 별 조사 자료, 2013년 이후에는 4월, 6월, 7월, 9월 자료가 추가되었다. 전체 자료의 수는 939로 훈련용 자료(training dataset) 80%(749개)와 평가용 자료(testing dataset) 20%(190개) 비율로 분리했다. 자료에서 모델 훈련에 불필요한 항목(생태구명, 정점명, 관측년도, 관측월, 조사일자, 날씨, 수심)은 제거하였다. 그리고 투명도(SD), 저층 용존산소(DOBot), 표층 용존무기질소(DINSur), 표층 용존무기인(DIPSur), 표층 클로로필a(Chl-aSur) 자료를 이용하여 해양수산부고시 제2018-10호 「해양환경기준」에 명시된 WQI 산출 방식(Table 2)에 따라 WQI 등급을 라벨링(labeling)한 출력(output) 자료를 사용하였다.
Table 1.
Information on monitoring dataset for modelling
Table 2.
Scoring method of each parameter in Central West region
수질 조사 결과의 결측값(missing value)을 포함하는 일부 자료는 사용하지 않았으며, Min-Max scaling을 통해 입력(input) 자료를 0-1 범위로 정규화(normalization)했다. 시화호 유입 하천의 연평균 DIN 자료는 해양수산부 연구 사업 보고서 결과를 인용했다(MOF, 2021).
2.3 모델 선정 및 알고리즘
모델 선정은 문헌 조사를 통해 결정했다. 기존 문헌 중 순위 상위 20% 이내의 학술지에서 2021에 보고된 모델들 중 가장 WQI 예측 결과가 우수한 모델의 알고리즘을 선택했다. 해당 문헌과 모델을 Table 3에 요약했다. 이 연구의 자료를 이용하여 각 모델들의 성능을 비교하였을 때 WQI 예측 성능이 우수한 AdaBoost, TPOT 알고리즘을 사용하였다. 모델링(modeling) 작업은 Python (Ver. 3.9.5)의 Scikit-learn (Ver. 1.0.1)과 TPOT (Ver. 0.11.7) 라이브러리(library)를 Visual studio code (Microsoft) 코드(code) 편집기에서 실행하여 수행하였다.
Table 3.
Bibliometrics on WQI predictive models for algorithm screening
| Author, Year | Algorithm |
| Tiyasha et al., 2021 | H2O Deep Learning (DL) |
| Guo and Lee, 2021 | Adaptive Boosting (AdaBoost) |
| Prasad et al., 2021 | Tree-based Pipeline Optimization (TPOT) |
| Deng et al., 2021 | Support Vector Machine (SVC) |
| Imani et al., 2021 | Bayesian Regularization (BR)-Multilayer Perceptron (MLP) |
| Asadollah et al., 2021 | Extremely Randomized Trees (ERT) |
2.3.1 Adaptive Boosting (AdaBoost)
AdaBoost는 약한 학습기(weak learner)의 예측 오류(error)에 대해 가중치(weight)를 부여하여 예측 성능을 강화(boosting)시킨다(Zhu et al., 2009). 개별의 약한 학습기는 순차적으로 학습하면서 개별 가중치를 부여하여 보다 강화된 학습기(boosted learner)를 만든다. 이 연구는 DT를 약한 학습기로 사용하였다. 노드(node)가 하나이고, 잎(leaf)이 2개인 구조를 가진 그루터기(stump)가 각각의 약한 학습기를 의미한다. 각 그루터기에서 오류를 범한 자료에 더 높은 가중치를 부여해 다음 그루터기를 최적화한다.
먼저 n개(i = 1, 2, ... , n)의 샘플(sample)자료에 대한 각각의 초기 가중치를 이라 설정한다. 은 다중 클래스(class)의 약한 학습기로 가중치를 적용하여 샘플 자료를 분류한다. 그리고 Eq. 1로 오차율(error rate)를 계산한다.
여기서 m은 반복 단계(iteration), 은 입력(input) 자료 샘플, 는 타깃(target)값일 때 는 오분류(misclassification)이면 1, 일치하면 0을 의미한다. 따라서 모든 샘플의 가중치 합에서 오분류한 샘플들의 초기 가중치 합을 나누면 약한 학습기의 오차율을 구할 수 있다.
그리고 약한 학습기가 얼마나 최종 분류 결과에 영향을 미치는지 나타내는 상수(중요도) 를 Eq. 2으로 계산한다.
여기서 K는 클래스의 수를 의미한다. 약한 학습기의 분류 오류가 작을수록 는 양(positive)의 값을 갖게 된다.
Eq. 3를 이용하여 새로운 가중치를 설정한다.
여기서 오분류일 경우 새로운 가중치를 설정해준다.
샘플의 가중치를 정규화(normalization)시키고 최종적으로 Eq. 4와 같이 각 클래스의 분류 결과값을 계산한다.
여기서 argmax (arguments of maxima)는 모든 약한 학습기의 중요도 ()의 합이 가장 큰 클래스 값 (k)을 반환한다.
2.3.2 Tree-Based Pipeline Optimization (TPOT)
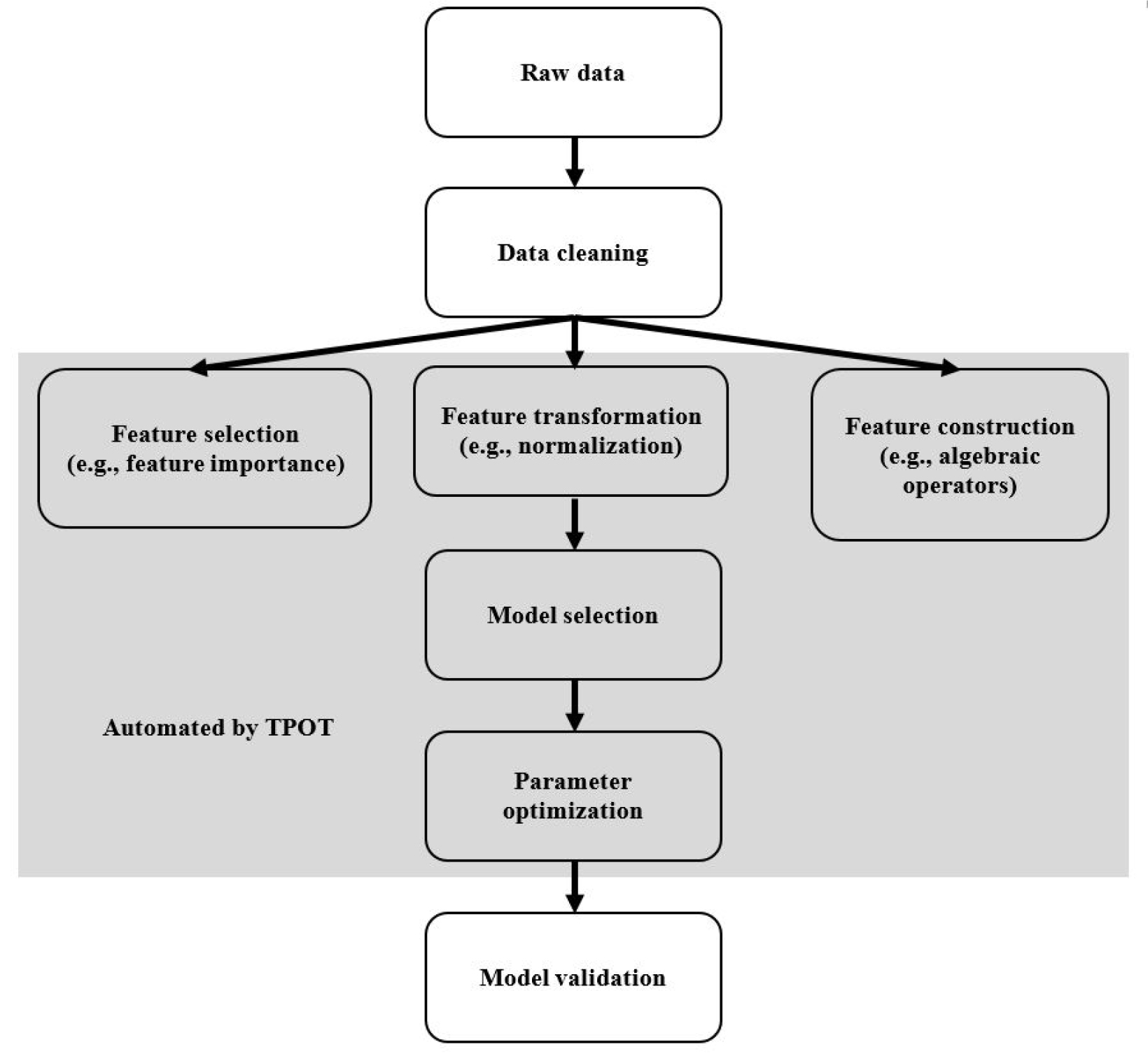
TPOT은 오픈 소스 소프트웨어(open-source software) 패키지(package)로 ML 파이프라인(pipeline)의 자동화된(automated) 최적화(optimization)를 가능하게 한다(Olson et al., 2016). Python의 Scikit-learn 라이브러리를 ML 메뉴로 이용했다. 나무 구조의 파이프라인(tree-based pipeline)을 형성하여 변수 선택(feature selection), 변수 변형(feature transformation), 변수 구축(feature construction), 모델 선택(model selection), 파라미터 튜닝(tuning)을 자동화할 수 있다(Fig. 2). 나무 구조의 파이프라인을 자동화하기 위해 유전 프로그래밍(genetic programming, GP)이라는 진화 컴퓨터 기술(evolutionary computing)을 사용한다. GP는 여러 개의 파이프라인을 생성하여 최적의 파이프라인으로 진화시킨다.
2.4 교차검증 및 하이퍼파라미터 튜닝
모델의 최적 하이퍼파라미터(hyperparameter)를 찾기 위해 GridSearchCV라는 교차검증(cross validation) 기반 하이퍼파라미터 튜닝 방식을 채택했다. 각 모델 별로 하이퍼파라미터 그리드(grid)를 구성하고 교차검증 시 폴드(fold)의 수는 3으로 지정하였다. AdaBoost 모델은 강화 학습 반복수(n_estimators), 개별 학습기 중요도(learning_rate), 노드 분할 평가 함수(base_estimator__criterion), 노드 분할 방식(base_estimator__splitter)을 하이퍼파라미터로 설정하였다.
2.5 변수 중요도(Feature Importance)
중요한 설명 변수만을 선택하여 모델을 훈련하면 성능이 향상될 수 있어 recursive feature elimination (RFE)라는 변수 선택 방식을 사용하였다. RFE는 변수 선택 방식 중 후진(backward) 소거법으로 모든 수질 인자가 포함된 모델에서 가장 불필요한 인자를 하나씩 소거해가면서 변수 중요도 상위 10개의 인자들을 확인했다. 그리고 그 중 공통적으로 선정된 인자를 추출하였다. 또한 WQI 산출식에 필요한 수질 인자(SD, DOBot, DINSur, DIPSur, Chl-aSur)들 간의 중요도도 비교하였다.
2.6 민감도 분석(Sensitivity Analysis)
민감도 분석은 모델 성능에 대한 수질 인자들의 상대적인 중요도를 확인하여 적합한 인자들의 조합(combination)을 탐색하고 WQI 등급, 조사 정점 및 시기 별 예측 성능을 비교했다. 변수 중요도 분석 결과에서 얻은 모델들의 공통 중요 인자들을 ‘leave-one-out (stepwise)’ 방식으로 조합해 변수에 대한 민감도를 비교하였다. 그리고 최적 입력 변수 조합으로 훈련한 모델을 정점 별 자료에 대해 평가를 하여 정점 별 민감도를 비교하였다. 해당 조사 기간의 월 평균 강우량을 비교한 결과 중 2월은 수질이 가장 좋고(2등급) 강우량이 적었으며(27.5 mm) 8월이 가장 수질이 나쁘고(4등급) 강우량이 많았다(238.8 mm). 각 시기의 수질 조사 자료에 대해 모델을 평가하여 시기 별 민감도를 비교하였다. 이때 훈련용 자료에서 해당 시기(2월, 8월)의 조사 자료는 제외하고 훈련시켰다. 시공간적인 자료의 변화 외에도 모델의 WQI 등급 별 예측 민감도를 비교하여 해당 모델이 취약한 예측 등급을 확인하였다.
2.7 모델 성능 평가
모델 훈련 후 모델의 예측 성능 평가는 평가지표들(metrics)을 비교하여 평가하였다. 평가지표는 WQI 등급을 분류하는 과거 문헌에서 가장 많이 사용하였던 정확도(accuracy), 정밀도(precision), F1 score, Log loss (negative log-likelihood)를 선정하여 각 모델의 성능을 비교하였다. 각 평가지표의 계산식은 Eq. 5, 6, 7, 8과 같다. 이 연구에는 자료의 클래스 분포 상 불균형(imbalance)을 고려하여 가중 산술평균(weighted arithmetic mean)을 적용하여 정밀도와 F1을 구하였고 이에따라 정확도는 민감도(recall)값과 동일하다.
여기서 실제값(actual value)과 예측값(predicted value)이 일치하면 TruePositives (TP)와 TrueNegatives (TN), 불일치하면 FalsePositives (FP)와 FalseNegatives (FN)이다. N은 샘플의 수, M은 클래스(class)의 수, 는 i번째 샘플의 예측 클래스와 j번째 클래스의 일치 여부(0 또는 1), 는 i번째 샘플이 j번째 클래스로 분류될 확률(likelihood)이다.
3. 결 과
AdaBoost과 TPOT 알고리즘 기반 WQI 예측 모델의 입력 변수 조합 별 WQI 분류 성능을 비교·평가하였다. 여기에 각 변수들의 중요도가 모델 성능에 미치는 영향에 대해 평가하였다. 그리고 시공간과 WQI 등급 별 자료에 대해서도 모델 성능을 평가했다. 최종적으로 최적의 입력 변수 조합으로 개발한 모델의 성능을 비교하였다.
3.1 모델 성능 비교
모든 수질 인자를 입력 자료로 활용한 경우에 TPOT 알고리즘 기반의 모델이 AdaBoost 모델보다 더 높은 예측 정확도(F1AdaBoost: 0.780, F1TPOT: 0.867)를 보였다(Table 4). 수질 인자 중 기존 WQI를 계산하기 위해 사용되는 인자(SD, DOBot, DINSur, DIPSur, Chl-aSur)들만으로 모델링을 할 경우에도 TPOT 모델에서 더 우수한 예측결과(F1AdaBoost: 0.771, F1TPOT: 0.875)를 보였다(Table 5). 입력 변수의 감소(feature reduction)로 각 모델의 정확도는 크게 감소하지 않았다. 그러나 TPOT 모델은 WQI를 계산하기 위해 사용되는 인자들만 입력 자료로 사용할 경우 더 좋은 결과를 보였다.
Table 4.
Performance metrics for WQI predictive models using whole variables in testing phase
| Algorithm | Accuracy | Precision | F1 | Log loss |
| AdaBoost | 0.779 | 0.793 | 0.780 | 7.635 |
| TPOT | 0.874 | 0.869 | 0.867 | 0.343 |
Table 5.
Performance metrics for WQI predictive models using important variables (SD, DOBot, DINSur, DIPSur, and Chl-aSur) in testing phase
| Algorithm | Accuracy | Precision | F1 | Log loss |
| AdaBoost | 0.763 | 0.792 | 0.771 | 8.180 |
| TPOT | 0.879 | 0.876 | 0.875 | 1.350 |
3.2 변수 중요도
모든 수질 인자들 중에서 DOBot가 WQI와 가장 좋은 상관관계(correlation)를 보였다(Fig. 3). RFE 방식으로 중요한 설명 변수를 추출한 결과 AdaBoost, TPOT 모델에서 SD, tempSur, tempBot, DOBot, DINSur, DIPSur, Chl-aSur가 공통 중요 변수였고 가장 중요한 변수는 DOBot였다(Table 6). 그 다음으로 AdaBoost 모델에서는 DIPSur > Chl-aSur > SD > DINSur > tempSur > DOSur > tempBot > salinitySur > DINBot, TPOT 모델에서는 Chl-aSur > DINSur > SD > tempBot > DIPSur > tempSur > NO2-NBot > TPBot > DIPBot 변수 중요도 순이었다(Table 6). 이는 TPOT 모델은 AdaBoost 모델과 다르게 WQI 등급 분류를 위해 용존무기인(DIP)보다 수온(temp)이나 용존산소(DO)에 대한 의존도가 큰 것을 의미한다. 기존 연구에서 연중 기온차가 큰 지역의 경우는 수온이 식물성 플랑크톤의 성장에 영향을 주는 인자였다(Deng et al., 2021). WQI 계산에 필요한 입력 변수(SD, DOBot, DINSur, DIPSur, Chl-aSur)로 축소할 경우 두 모델에서 DOBot의 중요도가 가장 높았고 DINSur의 중요도가 가장 낮았다. 하지만 모든 수질 인자들을 고려했을 때와 달리 TPOT 알고리즘에서는 DIPSur가 SD, DINSur보다 중요한 변수였다(DOBot > Chl-aSur > DIPSur > SD > DINSur).
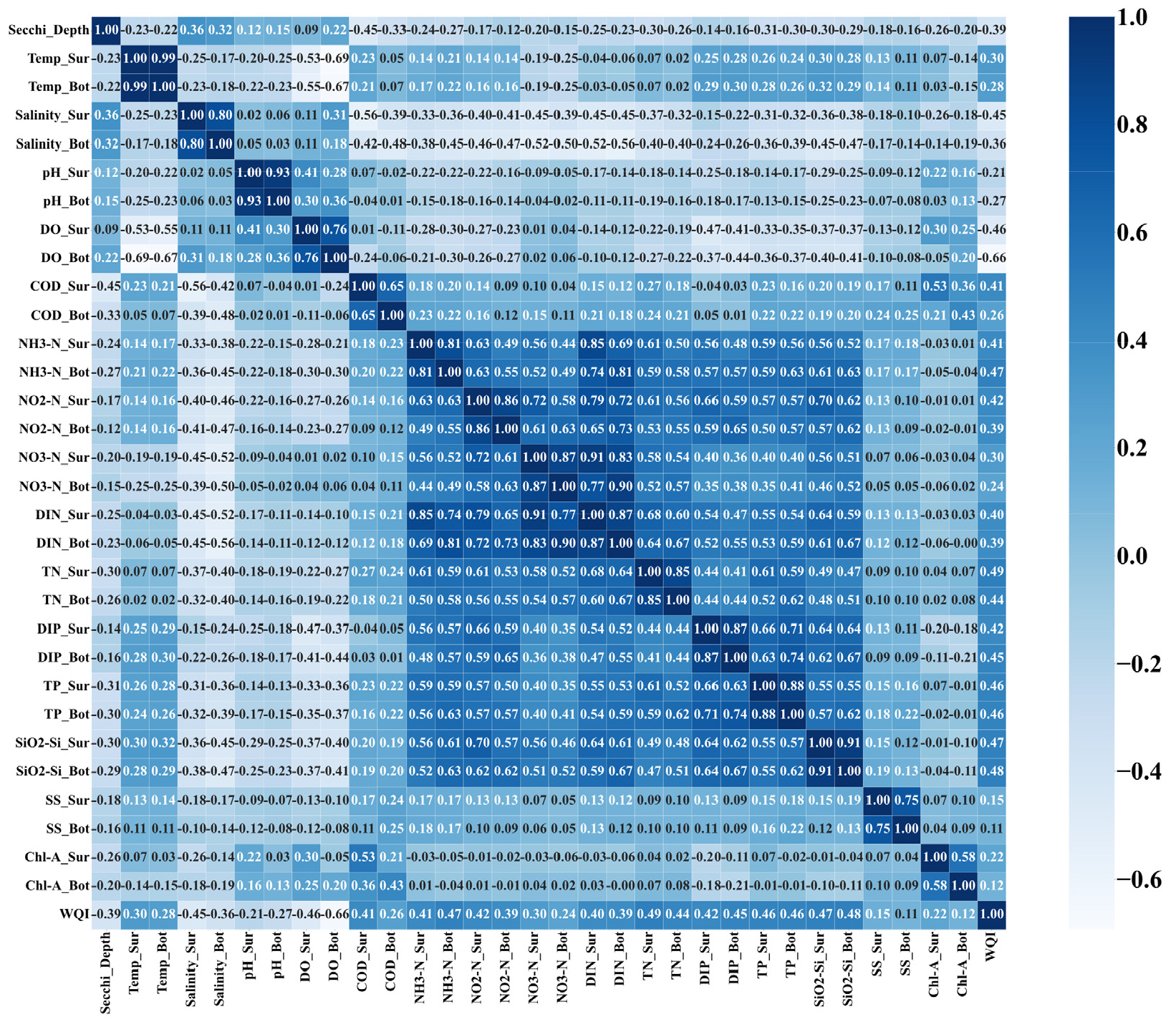
Table 6.
The important 10 input variables and their ranks for each model
| Feature | AdaBoost | TPOT |
| Secchi disk depth (SD) | 4 | 4 |
| tempSur | 6 | 7 |
| tempBot | 8 | 5 |
| salinitySur | 9 | - |
| DOSur | 7 | - |
| DOBot | 1 | 1 |
| NO2-NBot | - | 8 |
| DINSur | 5 | 3 |
| DINBot | 10 | - |
| DIPSur | 2 | 6 |
| DIPBot | - | 10 |
| TPBot | - | 9 |
| Chl-aSur | 3 | 2 |
3.3 민감도 분석 결과
민감도 분석 결과 AdaBoost 모델은 SD, DOBot, DIPSur, Chl-aSur, TPOT 모델에서는 SD, DOBot, DINSur, Chl-aSur 입력 변수 조합에서 가장 우수한 성능(F1AdaBoost: 0.758, F1TPOT: 0.830)을 보였다(Table 7). 한편, WQI 계산에 필수적인 수질 인자(DINSur 또는 DIPSur)를 제외한 입력 자료로 훈련한 모델을 평가했을 때 성능 면에서 크게 저하되지 않았다. 이는 DINSur이나 DIPSur와 같은 부영양화 원인 인자가 부영양화 결과 인자(SD, DOBot, Chl-aSur)에 비해 상대적으로 모델 예측 성능에 큰 영향을 미치지 않는 것을 의미한다. 또한, TPOT 모델에서 DIPSur의 변수 중요도가 DINSur보다 높았으나 DIPSur을 제외한 입력 변수 조합에서 더 높은 예측 성능을 보였다.
공간 민감도 분석은 정점 별 평가 자료에 대한 최적 모델 예측 성능을 비교하였다. AdaBoost 모델에서는 시화호 하류 9번 정점에서 가장 높은 예측 성능(F1AdaBoost: 0.863)을 보인 반면 바로 우측에 위치한 형도 인근 2번 정점의 자료에 대해 가장 낮은 성능(F1AdaBoost: 0.702)을 보였다(Table 8). TPOT 모델에서는 시화호 하류 배수갑문, 시화방조제 인근 3, 9번, 형도와 우음도 갯벌 인근 1번 정점에서 높은 WQI 등급 분류 정확도(F1TPOT: 1.000)를 보였고 상류 5번 정점(F1TPOT: 0.651)에서 낮은 정확도를 보였다(Table 8).
Table 7.
Each model performance for the 5 best input combinations in testing phase
Table 8.
Evaluation of each best model on spatial sensitivities
조사 시기 별 자료를 대상으로 최적 모델을 평가하였을 때 두 모델 모두에서 2월(F1AdaBoost: 0.587, F1TPOT: 0.556) 보다는 하천 유입이 큰 8월(F1AdaBoost: 0.801, F1TPOT: 0.800)에 WQI 예측 성능이 높았다(Table 9).
Table 9.
Evaluation of each best model on temporal sensitivities
| Algorithm | Month | Accuracy | Precision | F1 |
| AdaBoost | Feb. | 0.642 | 0.582 | 0.587 |
| Aug. | 0.803 | 0.812 | 0.801 | |
| TPOT | Feb. | 0.617 | 0.540 | 0.556 |
| Aug. | 0.803 | 0.806 | 0.800 |
마지막으로 등급 별 입력 자료에 대한 모델의 성능 평가 결과 AdaBoost 모델은 WQI 등급 1등급(F1AdaBoost: 0.981)에서 가장 높은 분류 정확도를 보였고, 3등급(F1AdaBoost: 0.651)에서 가장 낮았다(Table 10). 반면, TPOT 모델은 2등급(F1TPOT: 0.993)에 대해서 성능이 가장 높았고, 4등급(F1TPOT: 0.516)에서 가장 낮은 정확도를 보였다(Table 10).
Table 10.
Evaluation of each best model on WQI class sensitivities
3.4 고찰
AdaBoost와 TPOT 두 가지 알고리즘을 모델 성능 면에서 비교하였을 때 TPOT 모델이 더 우수하였다. AdaBoost 모델은 고정된 하이퍼파라미터들을 탐색하여 최적의 하이퍼파라미터를 선택하였지만 TPOT 모델은 GP 알고리즘 기반으로 ML 파이프라인을 최적화하여 사용자의 수동적인(manual) 선택 없이 최적화를 자동화할 수 있다. 결과적으로 TPOT 모델은 더욱 최적화된 모델링이 가능하며 정밀한 하이퍼파라미터 튜닝도 가능하다. 기존 연구도 다른 ML 알고리즘(DT, RF)에 비해 TPOT과 같은 AutoML 알고리즘으로 훈련한 모델이 WQI 등급 분류에서 더 높은 성능을 보였다(Prasad et al., 2021). 또한 GP 알고리즘으로 중요 변수를 선택하여 모델을 최적화하였을 때 WQI 예측 성능이 보다 개선되었다(Abba et al., 2020). 이 연구도 이전 연구 결과와 유사하게 입력변수 조합 보다는 알고리즘이 모델의 성능에 더 큰 영향을 미쳤다(Asadollah et al., 2021).
두 알고리즘 모델의 변수 중요도는 DOBot가 가장 중요도가 높고 DINSur이 가장 낮았다. 이전 연구 결과에서 용존산소(DO)는 수생태계(aquatic ecosystem)를 대표하는 수질 인자로 WQI 예측 모델의 입력 변수 중 가장 중요하다고 보고되었다(Abba et al., 2022). 민감도 분석에서 알고리즘 별 최적 입력 변수 조합은 AdaBoost 모델의 경우 SD, DOBot, DIPSur, Chl-aSur, TPOT 모델의 경우 SD, DOBot, DINSur, Chl-aSur였다. 민감도 분석에서 SD, DINSur, DIPSur 변수의 제거는 모델의 성능에 큰 영향을 미치지 않았으나 DOBot, Chl-aSur는 매우 중요하였다. 공간 민감도는 시화호 상류의 5번 정점(산업단지 인근)에서 낮은 분류 성능을 보였다. 이는 산업단지의 비점오염원에서 유입되는 물질의 비선형적인 변동(fluctuation) 때문에 훈련용 자료에서 뚜렷한 패턴(pattern)을 학습하기 어려웠기 때문으로 판단된다. 이와 반대로 산업계 오염원의 영향이 상대적으로 적은 정점 1, 3, 9에서는 WQI 등급 예측 성능이 우수하였다. 이전 연구도 유사하게 불법 방류와 같은 오염원에 의한 영향을 받는 상류보다 중하류 유역에서 더 높은 WQI 예측 성능을 보였다(Khozani et al., 2022). 그리고 조력발전소 인근 정점(S10)은 해수유통으로 인해 해양환경특성의 변동이 크고 DOBot가 급격하게 증가하여(Ra et al., 2013) WQI 등급 분류에 낮은 성능을 보였다. 계절별 민감도 분석은 과거 연구와 유사하게 하계(8월)에 예측 정확도가 높았다(Ho et al., 2019). 이는 강우 빈도가 높은 8월에 하천을 통해 유입되는 용존영양염(DIN, DIP)이 증가하여 부영양화 결과 인자들(SD, DO, Chl-a)의 변화가 뚜렷해져서(Rho et al., 2012) WQI 등급이 더 정확하게 분류되었다고 판단할 수 있다. 한편, 일부 연구는 강우량이 많은 시기에는 모델 예측 성능이 저하된다고 보고했다(Bui et al., 2020).
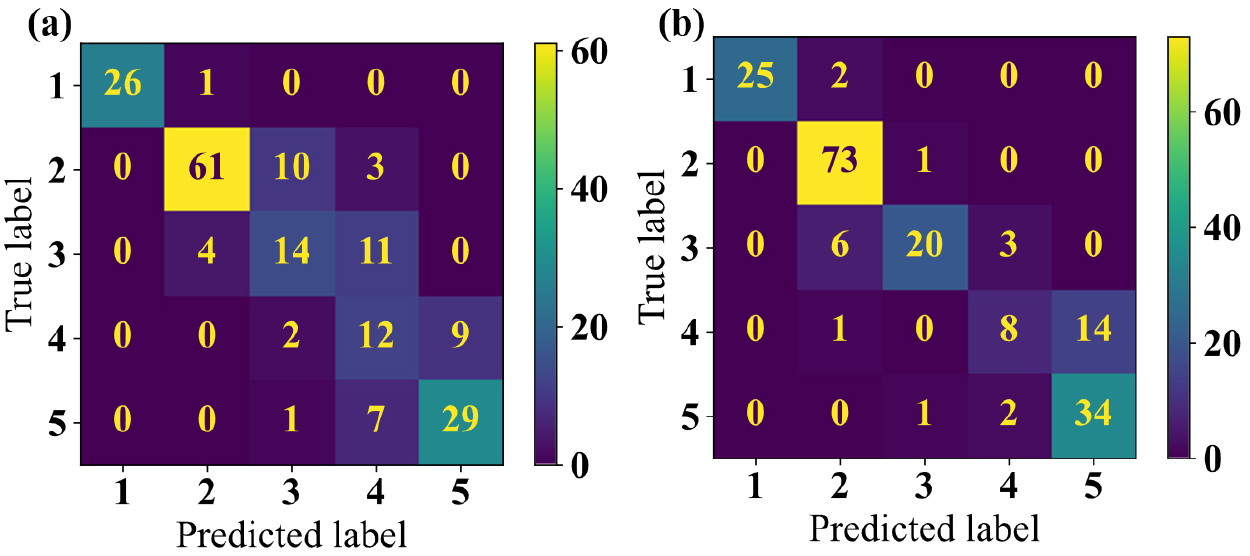
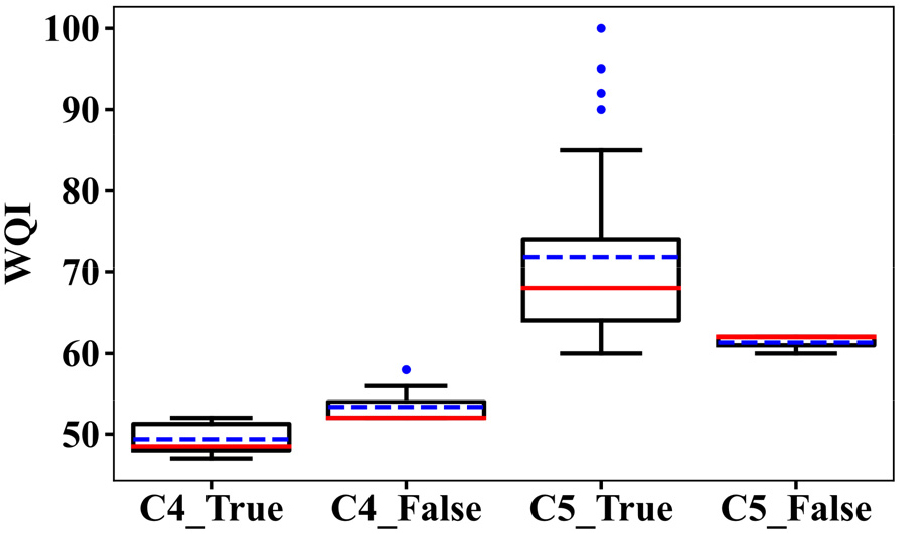
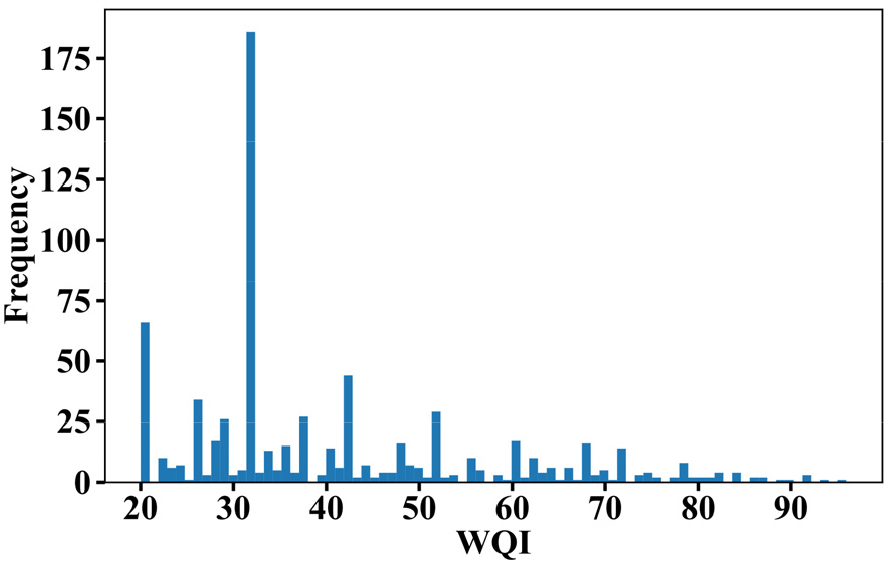
각 모델의 WQI 등급 분류를 오차행렬(confusion matrix)로 표현했을 때 WQI 등급 분류 성능이 TPOT 모델에서 더 우수한 것을 확인할 수 있다(Fig. 4). 하지만 WQI 등급 1, 4등급에서는 AdaBoost 모델이 더 정확하게 분류를 했다. TPOT 모델은 실제값이 4등급이었으나 예측값은 5등급으로 오분류하는 경우가 가장 많았다. Fig. 5는 최적 TPOT 모델의 평가용 자료 중 WQI를 등급별 예측 오류 여부(true or false)에 따라 상자 수염 그림(boxplot)으로 나타내었다. WQI 등급 4등급 중에서 높은 WQI (52-58)의 자료는 WQI 등급이 오분류 되는 경향(C4_False)이 있었다. 또한 4등급 중에서 고농도의 DOBot (5.60-8.34 mg L-1)가 정확하게 분류가 되었고 저농도의 DOBot (4.85-6.84 mg L-1)에선 오분류가 발생했다. 훈련용 자료에서 WQI 등급 1등급(83개), 4등급(80개) 수가 상대적으로 부족하였다. Fig. 6에 훈련용 자료의 WQI 빈도(frequency)를 제시했다. 4등급의 WQI (47-59) 후반부의 자료 수가 부족한 것을 보아 4등급과 5등급 사이 경계의 자료에 대한 WQI 등급 분류 성능이 취약할 수 있다. 이전 연구의 결과에서도 등급 별 자료의 수와 WQI의 분산(variance)이 WQI 등급 예측 성능에 영향을 주는 것으로 보고되어 있다(Tiyasha et al., 2021).
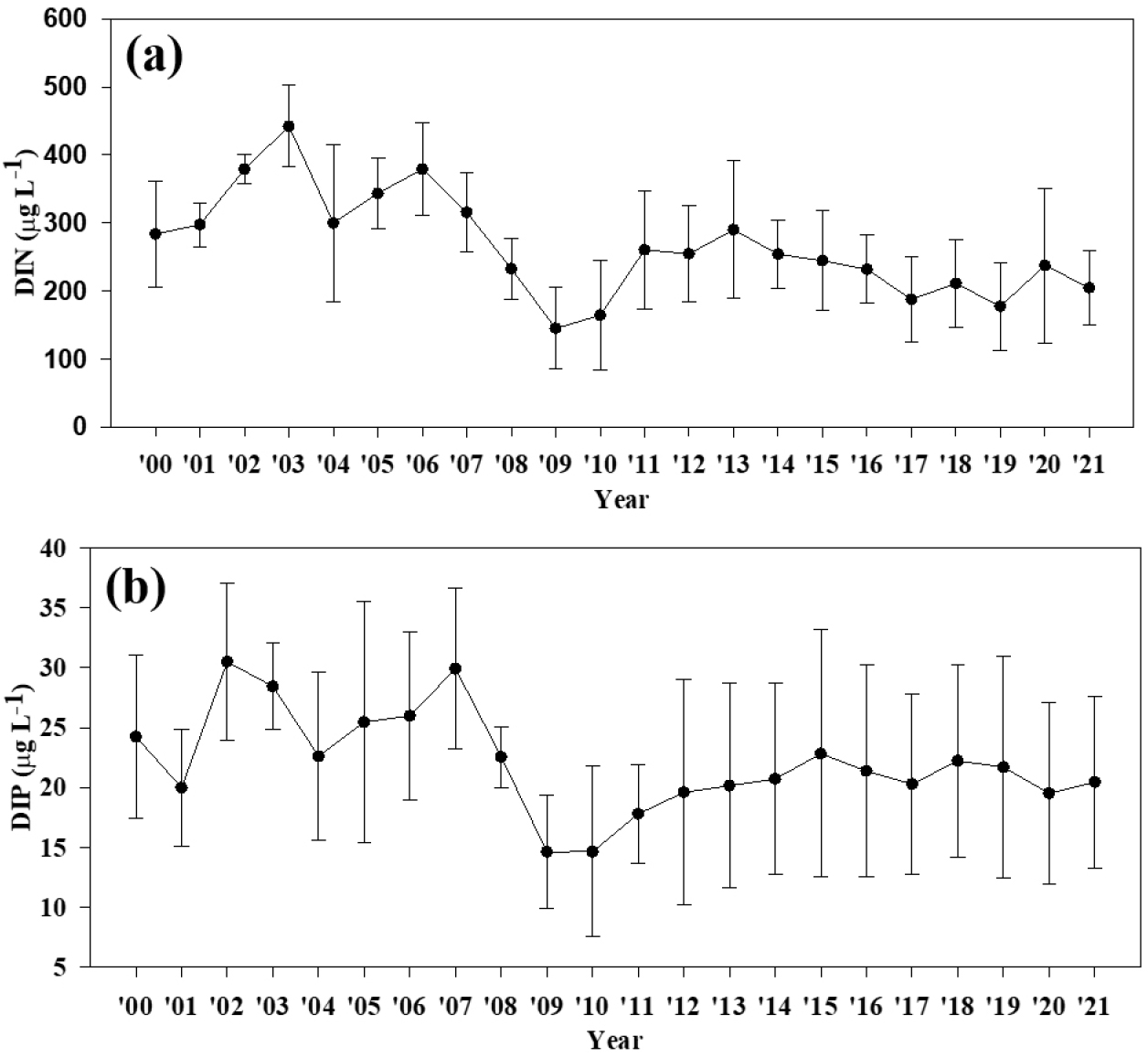
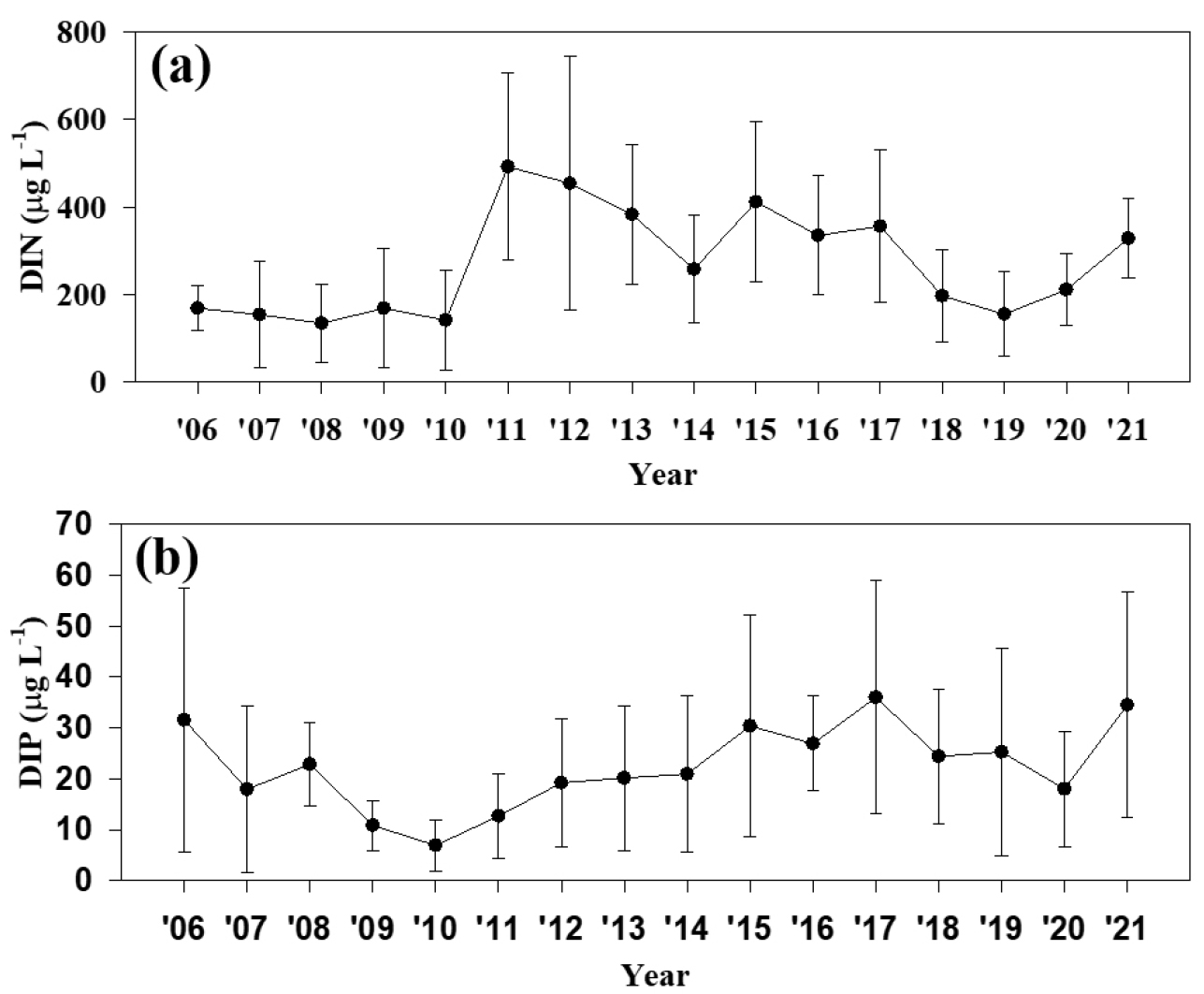
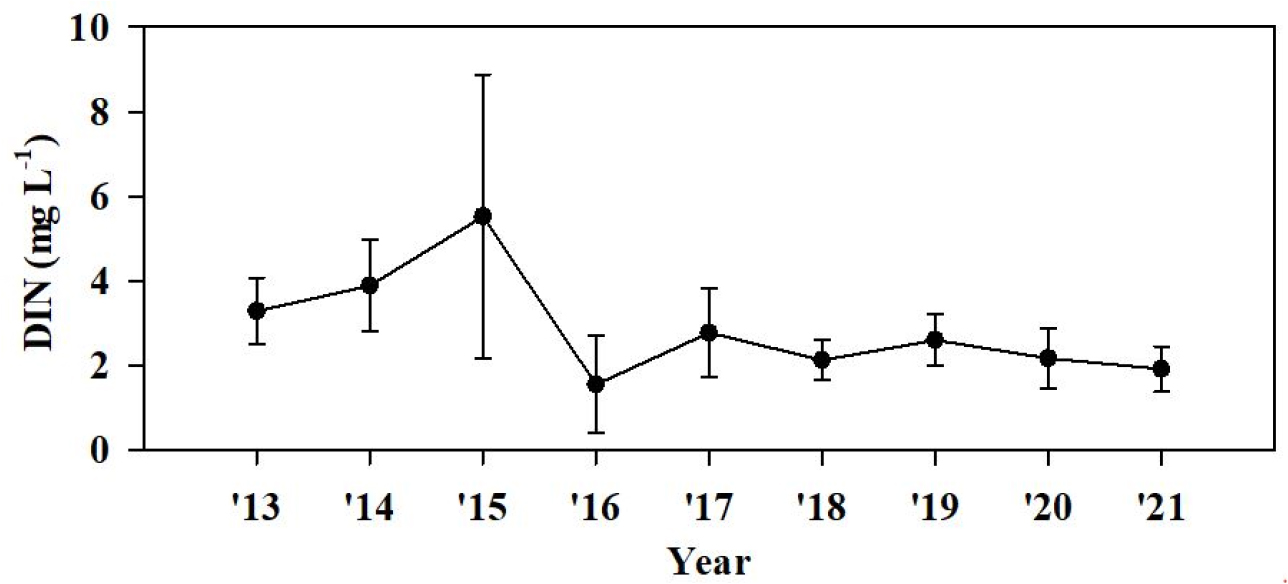
현재 사용되는 WQI는 과거(2000-2007년)의 수질로 평가되었다. 반면, 이 연구에서 사용한 해양환경측정망 자료는 2004년 이후 자료로 현 시화호의 수질 평가에 오류를 초래할 수 있다. 최근 하수처리장의 증설과 해수 유통 등으로 수질이 개선되었다고 가정하면 현재의 수질 조사 자료를 입력하였을 때 수질 인자 별 기준값과 등급 간 WQI의 경계가 달라질 수 있다. 그리고 WQI를 산출할 때 수질 인자 별 기준값이 생태구 별로 다르다. 서해중부(Central West) 생태구의 DIN 기준치(425 μg L-1)는 다른 생태구(동해, 대한해협, 서남해역, 제주)보다 높은 값으로 설정이 되어 있어 DINSur 농도가 다른 생태구의 해역보다 높아도 수질이 더 좋게(WQI가 낮게) 평가될 수 있다. 서해중부의 연평균 DINSur 농도는 기준값보다 작은 경우가 많았고 2006년 이후 점차 감소하는 추세이다(Fig. 7a). 시화호의 연평균 DINSur 농도는 2011년 해수 유통 이후 감소하고 있고 기준값보다 낮은 시기가 많아 WQI에 큰 영향을 미치지 못하였다(Fig. 8a). 여기에 DIN은 수질 인자 중 하천 영향을 가장 많이 받는 인자로 알려져 있다(Rho et al., 2012). 그러나, 시화호는 비강우 시 하천으로 유입되는 DIN 농도가 점차 감소하고 있다(Fig. 9). 서해중부와 시화호의 연평균 DIP 농도도 기준치(30 μg L-1)보다 작은 값이 많았으며 서해중부는 2007년 이후부터 감소하였고 시화호는 2006년 이후부터 감소하다 증가하였다(Figs. 7b, 8b). DINSur과 DIPSur가 저농도로 WQI의 변화에 큰 기여를 하지 못하고 오히려 일부 시기와 정점의 이상치(outlier)로 인해 모델의 성능을 저하시켰다. 그리고 WQI 산출식의 가중치도 결과 인자(SD, DOBot, Chl-aSur)보다 작다. 이전 연구는 담수와 다르게 해수에서 질소가 인보다 부영양화에 대해 중요한 제한 인자(limiting factor)라고 제시했다(Deng et al., 2021). 이러한 이유로 TPOT 모델에서 DIPSur을 제외한 입력 변수 조합(SD, DOBot, DINSur, Chl-aSur)에서 높은 분류 정확도를 보인 것으로 판단된다.
시화호의 지속적인 개발로 인해 수질 인자들의 변동성이 매우 커 수질을 명확하게 진단할 수 있는 WQI의 예측이 쉽지 않다. 또한 각 수질 인자 간의 상관관계와 WQI와의 인과관계가 매우 복잡한 비선형성을 가지고 있다. 이 연구결과는 WQI 등급 분류 성능이 우수한 TPOT 알고리즘을 이용하여 DINSur 또는 DIPSur 수질인자를 제외한 수질 자료로 훈련한 모델을 평가하였을 때 우수한 예측 성능을 보였다. 실제로 방대한 양의 수질 자료의 WQI 등급 예측 시 입력 변수를 축소하여도 적정한 성능을 나타내는 모델일수록 활용 가능성이 높다고 알려져 있다(Abba et al., 2022). 비록 WQI 등급 4등급에서 자료의 정성·정량적인 질의 한계로 인해 선정 모델의 분류 성능이 미흡한 수준이었지만 향후 수질 자료가 축적될 경우 보완이 가능할 것이다. 그리고 시화호 일부 정점의 수질자료 값을 입력하였을 때 낮은 분류 정확도를 나타낸 것으로 보아 특정 정점에서 하천의 영향, 조력발전소 해수유통 등의 다양한 원인으로 수질 조사 자료의 변동이 크고 패턴을 훈련하기에 복잡한 경향을 보였다. 정점 5번과 같이 산업계 오염원이 우려되는 정점의 경우 지속적인 수질 모니터링이 필요하므로 보다 안정적인 모델의 예측 성능이 요구된다. 또한 시기별 민감도 분석에서는 2월 수질 조사 자료를 제외하고 훈련을 하여 낮은 정확도를 보였지만 2월 조사 자료를 일부 포함하여 훈련하면 향후 해당 시기의 WQI 등급을 예측하는데 어려움이 없을 것이다. 나아가 타 해역의 수질 조사 자료를 이용하여 알고리즘의 적합성(suitability)을 교차 분석(cross check)해 볼 필요가 있다.
4. 결 론
현재 효율적인 해양환경관리를 위해 수질 자료를 이용하여 해역의 수질을 표현하는 WQI가 널리 사용된다. 하지만 WQI를 산출하는 방법이 복잡하여 비숙련자가 방대한 수질 자료로 WQI를 산출할 때 어려움이 많다. 이러한 문제점을 해결하고자 두 가지 AI 알고리즘으로 과거의 수질 조사 자료와 WQI 등급을 훈련시켜 향후 변화가 예측되는 수질 조사 자료의 WQI 등급을 단시간 안에 정확히 분류하는 모델을 제안하였다. AdaBoost와 TPOT 알고리즘 중에서 TPOT 알고리즘 기반의 모델이 시화호의 수질 자료를 훈련하고 WQI 등급을 분류하는데 더 적합하였다. 더욱이 기존의 WQI 산출에 필수적인 5가지 수질 인자 중 DINSur 또는 DIPSur를 제외해도 유사한 수준의 분류 성능을 보였다. 따라서 향후 모델 성능이 더욱 향상된다면 수질 조사에 새로운 접근 방법을 제시할 수 있을 것으로 판단된다. 또한 수질이 나쁜 시기에 우수한 예측 성능을 보여 수질 악화에 주의가 요구되는 하계에 집중적인 수질 감시가 가능할 것으로 판단된다. 다만, 수질 변동이 큰 정점(S2, S5, S10)은 낮은 예측 정확도를 보였다. 향후 추가로 수집되는 수질 자료를 훈련시켜 성능을 향상시키고 복합 알고리즘 모델과 같은 더 진보된 AI 기술을 적용하여 일부 단점을 보완한다면 보다 정확한 WQI 등급 분류 및 수질 변화 예측이 가능할 것이다. 하지만 보다 지속가능한 해양환경관리를 위해서는 현재의 WQI 산출 방식을 개선할 필요가 있다. 모델에서 오분류로 평가되는 자료들을 재분석하여 현 평가 기준을 개선할 수 있을 것으로 판단된다. 또한 다양한 최신 AI 기술을 응용하여 해양환경을 보다 정밀하게 평가할 수 있는 새로운 지표(index)를 지속적으로 개발하는 방안도 고려해볼만 하다.
