

1. 서 론
2. 국립해양조사원의 무중단 지역해 수치예측자료 생산 전략
2.1 작업 스케줄러
2.2 시간 동기화
2.3 끊임없는 해양예측 자료 생산 전략
3. 쉘 스크립트를 이용한 무결 대용량 해양․ 기상 예측자료 내려 받기
3.1 기상예측자료 내려 받는 방법
3.2 해양예측자료 내려 받는 방법
4. 연산시스템 및 수치모델 수행 오류 알림 기능
5. 요 약
1. 서 론
정확도가 높으며 신속하고 안정적인 해양․대기 수치예측자료를 생산하기 위해서는 수치예측모델의 정확도 향상을 위한 연구개발뿐만 아니라 이를 빠르게 계산할 수 있는 고속 연산자원 확보와 안정적인 운영체계 개발이 무엇보다 중요하다. 해양․대기 수치예측모델들이 스케줄에 따라 매일 자동으로 수행될 수 있도록 운영체계를 구축하기 위해서는 기본적으로 운영기관의 컴퓨터 연산 자원과 컴퓨터 운영환경, 통신망, 운영인력 등 내부 여건들을 충분히 고려해야 한다(Kim et al., 2013). 기존 연구에서 수치예측모델의 필요성, 구성, 운영체계 등에 관해 개략적으로 설명한 연구논문들(Lee et al., 2009; Pinardi and Goppini, 2010; Kim et al., 2013; Park et al., 2015)은 많이 있지만, 구체적으로 수치모델 자동 수행체계를 설명한 연구논문 또는 기술노트는 거의 없다.
또한 계속적인 유지․운영을 위해서는 수치예측시스템의 이상 유무를 상시 모니터링하고 이상 발생 시에 신속하게 대응할 수 있는 전문 전담인력이 필요하다(Lee et al., 2009). 하지만 현재 국립해양조사원을 포함하여 대부분 국내 해양수치모델을 운영하고 있는 기관에서는 이러한 전문 전담인력이 거의 없거나 부족한 실정이다.
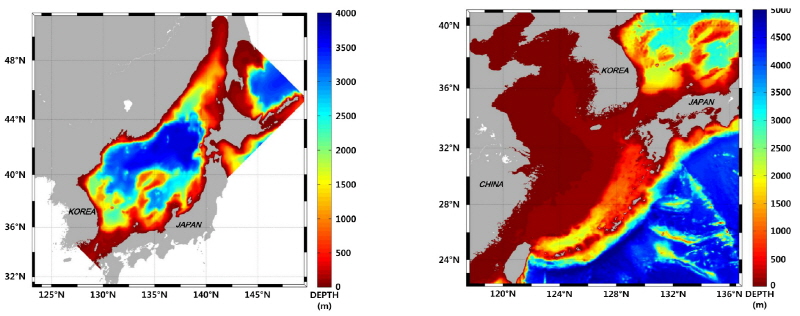
이 노트에서는 국립해양조사원에서 2012년부터 2016년까지 동해와 황동중국해 해역(Fig. 1)에서 매일 1시간 간격의 3일(72시간) 해류, 수온, 염분 등 수치예측자료를 생산하기 위한 자동수행 수치예측모델 운영체계의 구축과 운영 과정에서 발생한 문제점과 한계를 해결하면서 확보한 주요 기술 노하우(know-how)를 소개하고자 한다. 이를 위해, 3차원 지역해(regional ocean) 수치예측모델 운영에 있어서 기본적으로 필요한 작업 스케줄러(job scheduler)에 의해 외부자료를 내려 받는 방법과 수치예측시스템 오류 발생 즉시 해양 예측시스템 운영자들이 자동으로 상황을 파악할 수 있도록 하는 휴대전화 문자알림 기능에 관해 기술하였다.
2. 국립해양조사원의 무중단 지역해 수치예측자료 생산 전략
국립해양조사원은 ROMS (Regional Oceanic Modeling System) 수치모델을 기반으로 4년(2011∼2014년)에 걸쳐 고해상도(3 km 수평 격자 간격) 3차원 동해(The East Sea; ES) 수치예측시스템을 구축하였으며, 2년(2013∼2014년)에 걸쳐 동일 해상도의 황․동중국해(The Yellow and East China Seas; YES) 수치예측시스템 구축을 완료하였다. 현재 이들 지역해(YES, ES) 수치예측모델들의 자체 예측 성능 개선과 해양 자료동화 적용 등 예측 정확도 향상을 위한 고도화 연구를 수행 중에 있다. 이들 연구 성과는 예측자료를 매일 생산하는 현업 해양예측시스템에 반영되어 운용되고 있다.
이처럼 지역해 수치예측자료를 매일 생산하기 위해서는 기본적으로 수치모델 초기조건(initial condition)뿐만 아니라 개방경계(open boundary)에서 수온, 염분, 유속·유향, 해수면높이 등의 해양관측자료와 수행할 해양모델 영역과 기간에 대한 기온, 기압, 상대습도, 바람 등의 기상예측자료가 매일 필요하다. 따라서 지역해 해양예측모델의 예측기간은 우선적으로 주어진 기상예측자료의 기간과 예측 정확도를 고려하여 결정된다. 이를 고려하여 국립해양조사원은 2016년 말 현재 1시간 간격으로 72시간 동안 해양예측자료를 생산하는 체계를 수립하였다.
지역해 수치예측모델보다 더 넓은 광역예측모델을 함께 운영하지 않을 경우, 이들 입력자료는 국내․외 여러 수치예측 전문기관에서 자료동화 기법을 이용하여 생산·제공하는 해양·기상예측자료를 활용할 수 있다. 이 경우 지역해 수치예측모델을 매일 자동으로 수행하기 위해서는 광역 해양·기상예측자료를 매일 정해진 시간에 내려 받고, 예측을 수행하고자 하는 지역해양의 영역에 맞게 해양․기상예측자료를 처리하여 입력자료를 생산한다. 이와 관련하여 세 가지 측면, 즉 작업 스케줄러, 시간 동기화, 끊임없는 해양수치모델 구동전략을 살펴보고자 한다.
2.1 작업 스케줄러
작업 스케줄러는 앞서 언급한 수치모델 입력자료용 파일 내려 받기(download), 자료처리, 입력자료 생산, 해양예측모델 수행 등을 매일 정해진 시각에 자동으로 수행하는데 필요한 스크립트이다. 국립해양조사원은 유닉스(UNIX) 계열의 운영 체제에서 사용되는 시간 기반의 작업 스케줄러인 ‘cron’ 명령어를 이용하여 스케줄링을 수행하고 있다. 이 명령어는 shell 명령 호환이 가능한 ‘crontab’을 통해서 1분 단위까지 주기적인 작업을 설정하여 실행할 수 있으며, 시스템에서는 ‘crond’라는 데몬(daemon)이 항상 상주하면서 예약된 작업을 확인하고 실행한다.
2.2 시간 동기화
작업 스케줄러를 통해 매일 정해진 시간에 정해진 작업을 정확하게 수행시키기 위해서는 입력자료를 받는 해양예측시스템의 시간이 정확해야 한다. 이를 위해 ‘cron’을 이용하여 매일 0시에 타임 서버(time server)로부터 정확한 시간을 가져와 시스템에 적용하는 시간 동기화(time synchronization)를 수행한다. 현재 국내에는 여러 개의 타임 서버(time.kriss.re.kr, time.bora.net, ntp.kornet.net, ntp.postech.ac.kr 등)가 있으나 국립해양조사원에서 운영되고 있는 시스템은 그중 time.bora.net을 이용하여 시간 동기화를 하고 있다.
해양예측시스템과 같이 여러 대의 컴퓨터를 빠른 네트워크로 연결하는 방식을 사용하는 서버의 경우에 외부에서 로그인(login)이 가능한 마스터 서버(master server)를 두고 나머지 서버들은 외부와 연결이 차단되어 마스터 서버를 통하지 않고는 접속이 불가능한 경우가 일반적이다. 이들 서버 역시 시간 동기화가 필요하며, 그렇지 않을 경우 이 서버들 각각, 또는 마스터 서버와의 시간이 다르다면 해양예측모델 실행 시 자료들을 각 서버에 할당받고 다시 합치는 과정에서 문제가 발생할 수 있다. 따라서 이 서버들은 마스터 서버의 시간을 기준으로 동기화하도록 하였다.
시간 동기화를 수행하는 방법은 여러 가지가 있으며, 대표적인 명령어는 ‘ntp’와 ‘rdate’이다. ‘ntp’는 데몬 형태로 시스템에 항상 상주하여 타임 서버와 실시간으로 동기화를 수행하기 때문에 정확하며, 정밀도도 1/1,000초까지 맞출 수 있다. 그러나 항상 상주하는 데몬 때문에 시스템 자원을 상대적으로 많이 사용하는 단점이 있다. 반면 ‘rdate’는 1초 단위로 시간을 맞추기 때문에 ‘ntp’보다 정밀도는 떨어지지만 유틸리티(utility) 형식이기 때문에 사용자가 원하는 시각에 시간을 맞출 수 있다. 비록 ‘ntp’에 비해서 정밀도가 떨어지더라도 해양예측시스템은 고정밀 시간 동기화를 필요로 하지 않을 뿐만 아니라 연산에 시스템 자원을 투입하는 것이 더 효율적이기 때문에 상대적으로 시스템 자원을 적게 사용하는 ‘rdate’를 사용하여 시간 동기화를 수행하였다. 이렇게 얻어진 시간은 ‘hwclock’ 명령어를 거쳐서 하드웨어의 시간 역시 동기화한다(0 0 * * * rdate –s IP 주소 & hwclock –w). 이처럼 해양예측시스템에서 이루어지는 외부 입력자료 내려 받기 등의 모든 작업은 매일 0시 1회의 시간 동기화 수행 후에 실행된다(Table 1).

2.3 끊임없는 해양예측 자료 생산 전략
지역해 해양예측시스템의 무중단 운영과 관련한 구동 체계에 관해 살펴보고자 한다. 작업 스케줄러가 정확한 시각에 해양예측모델 수행이 필요한 자료를 내려 받을 수 있는 시스템을 구축하였다 하더라도 예기치 못한 문제가 발생할 수 있다. 예를 들어, 네트워크(network) 장애 또는 해양예측시스템에 필요한 자료를 제공하는 서버에 문제가 발생할 수 있다. 실제로 해양예측시스템에 입력자료로 사용되는 자료 중 미국 HYCOM (HYbrid Coordinate Ocean Model) 컨소시엄(consortium)에서 제공하는 예측자료는 미국 GODAE (Global Ocean Data Assimilation Experiment) 주도로 서비스되고 있으나 자료제공이 종종 중단되는 경우가 있다. 실례로 미 해군의 자료보관서버(data archive server) 문제로 인하여 2016년에 10월 6일부터 11일까지 6일간이나 자료제공이 중단되었다.
그러나 외부자료를 내려 받는데 어떠한 문제가 발생한다 하더라도 현업 해양예측시스템은 중단 없이 수행되어야 한다. 이를 위해서는 뜻밖의 긴박한 상황에 적절하게 대처할 수 있는 차선책을 잘 마련해야 한다. 해양예측모델 수행에 필요한 입력자료로는 수치모델의 초기장과 개방경계에서 입력되는 조석, 조류, 수온, 염분, 해수면 높이, 유속‧유향, 각종 기상자료 등이 필요하며, 이 중 초기장은 하루 전 생산된 자료를 사용하기 때문에 외부에서 구할 필요가 없다. 초기장과 달리 개방경계는 전날 외부 입력자료를 받지 못해 개방경계용 예측자료를 생산할 수 없을 경우를 대비하여 이틀 전 해양예측시스템에서 생산된 72시간 예측자료를 사용하도록 하고, 이 역시 생산된 자료가 없다면 사흘 전 생산된 예측자료에서 추출할 수 있도록 하였다. 이와는 별도로 HYCOM 예측자료를 받을 수 없을 때에는 다른 기관에서 제공하는 외부예측자료를 받아 해결하는 방법을 모색하고 있다. 또한 조위와 조류 입력용 자료는 Oregon 주립대학에서 생산․제공하고 있는 TPXO7.2 (http://volkov.oce.orst.edu/tides/global.html) 조화상수 데이터베이스(database)에서 얻어 사용하고, 자체적으로 ROMS에 탑재시킨 조석·조류 예측모듈을 통해 예측이 가능하기 때문에 별도로 외부 자료를 내려 받을 필요가 없다.
그럼에도 불구하고 외부 예측자료들을 장기간 내려 받지 못할 경우, 지역해 해양예측모델 수행이 중단될 수밖에 없다. 따라서 외부에서 받는 광역예측자료들이 공급되지 않는 최악의 상황을 가정하여 잘 알려진 해양․기상 기후장을 이용하여 사전에 수치예측모델에 필요한 입력자료를 제작하여 사용하도록 고안하였다. 개방경계 해양 입력자료와 기상 외력자료는 각각 WOA (World Ocean Atlas)자료와 COADS (Comprehensive Ocean-Atmosphere Data Set)자료로 미리 만들어 놓은 해양․기상 기후장을 사용한다(Fig. 2).
|
Fig. 2. A flowchart of a regional ocean automated forecast system operated by the Korea hydrographic and oceanographic agency. |
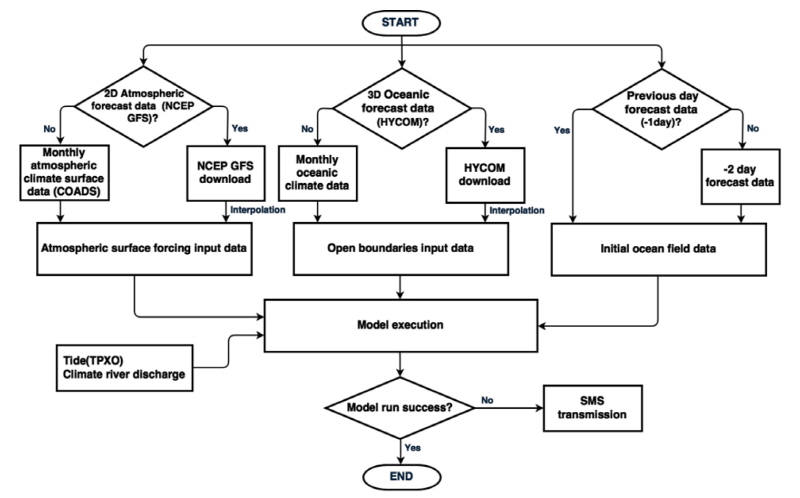
또한 단계별로 해양․기상 외부예측자료를 내려 받는데 실패한 경우에는 단문 메시지 서비스(Short Message Service, SMS)를 통하여 예측시스템 담당자에게 상황이 전달될 수 있도록 하였다. 이와 관련한 자세한 사항들은 제4장에서 살펴보도록 하겠다.
3. 쉘 스크립트를 이용한 무결 대용량 해양․기상 예측자료 내려 받기
3.1 기상예측자료 내려 받는 방법
지역해 예측모델을 통해 해양예측자료를 생산하기 위해서는 기본적으로 기상예측자료가 필요하다. 보통, 이 기상예측자료는 외부에서 제공되는 자료를 내려 받아 직접 해양예측모델의 기상 외력(forcing)자료로 사용하거나 또는 전 지구 기상예측자료를 외부에서 제공받아 시․공간적으로 상세한 국지 기상예측모델을 수행하기 위한 개방경계자료로 사용한다. 예를 들어, 미 해양대기청(National Oceanic and Atmospheric Administration, NOAA)의 NCEP (National Centers for Environmental Prediction) GFS (Global Forecast System) 기상예측자료를 파일 전송 프로토콜(File Transfer Protocol, FTP)을 이용하여 내려 받아 직접 WRF (Weather Research and Forecasting) 입력용 자료로 사용할 수 있다. NOAA의 GFS 산출물들(products)은 해당 홈페이지(http://www.nco.ncep.noaa.gov/pmb/products/gfs/#GFS)을 통하여 수평해상도(0.25°, 0.5°, 1.0°, 2.5°) 별로 grib2 형식의 기상예측자료를 제공되고 있다.
FTP를 사용하여 상대적으로 큰 용량의 파일을 내려 받는 경우, 도중에 통신이 순간적으로 끊기는 경우가 종종 발생한다. 이 때, 온전하지 않게 받은 파일을 입력하여 지역 상세 기상 수치예측모델을 수행하면 오류가 발생하는데 이를 방지하기 위해서는 외부에서 받은 파일에 대한 무결성 검사가 필수적이다. 따라서 일반적인 FTP 클라이언트 프로그램이 아닌 wget을 이용하여 파일을 내려 받는다. wget은 웹서버의 콘텐츠를 가져오는 유틸리티(utility)이나 FTP 프로토콜도 함께 지원하며, 무엇보다 이어받기를 가능하도록 해주는 –c 옵션은 통신 등의 문제로 내려 받은 자료에 문제가 발견되었을 경우 삭제 없이 복구를 가능하게 해주는 장점이 있다. 또한 –N 옵션은 원격지의 파일에 있는 내용을 로컬에 있는 파일과 비교하였을 때 새로운 내용이 있을 경우에만 내려 받기를 하는 기능으로 역시 무결성 검사의 기능을 갖고 있다. 그럼에도 불구하고 내려 받은 자료에 결점이 있을 가능성은 여전히 존재하기 때문에 별도의 무결성 검사가 필요하다. 내려 받은 파일의 이상 유무를 확인하여 재실행시킬 수 있는 가장 쉬운 방법 중 하나는 파일 크기(size)를 확인하여 일정 크기 이하일 경우에 다시 내려 받도록 하는 것이다. Table 2는 매일 3시간 간격으로 12시부터 84시까지 3일간의 NCEP GFS 파일을 내려 받는 배시 쉘(Bash shell)로 작성된 스크립트(script) 예이다.

이처럼 내려 받은 파일 크기를 비교하여 이상 유무를 판별하는 방법은 내려 받는 파일의 크기가 항상 같다면 가장 간편하고 효과적인 방법 중 하나이다. 그러나 NetCDF (Network Common Data Form) 파일형식으로 출력되는 해양수치모델과 달리 일반적으로 기상수치모델은 예측 결과를 GRIB (GRIdded Binary) 형식으로 출력되어 매 시간 저장되는 파일 크기가 일정하지 않다(Fig. 3). 예를 들어, Fig. 3에서 확인할 수 있듯이 제공되는 NCEP GFS 파일의 형식이 grib2로 각각의 파일마다 그 크기가 일정하지 않아 파일 크기를 비교하여 이상 유무를 판별하기는 쉽지 않다. 그 실패 예는 다음과 같다. 국립해양조사원에서는 제시한 배시 쉘 스크립트를 사용하여 두 대의 클러스터(클러스터1과 클러스터2)에서 각각 NCEP GFS 자료를 받아 이중으로 WRF 기상예측모델을 수행하고 있다. 2015년 6월 5일에 있었던 WRF모델 수행 오류는 클러스터1과 클러스터2에서 각각 받은 NCEP GFS 파일 중 ‘gfs.tl2z.pgrb2.lp00.f072’의 파일 크기가 각각 20,008,620 KB와 20,152,620 KB로 약간 차이를 보였다(Fig. 3). 그 결과 클러스터1에서 WRF 모델은 오류를 일으켜 결국 수행이 중단되었다. NCEP GFS의 grib2 파일형식처럼 받는 파일의 크기가 매번 일정하지 않고, 특히 그 차이가 1%이하로 아주 작을 경우에 일정한 파일 크기를 기준으로 이상 유무를 판별하는 방법은 완벽하지 않다. 이러한 문제점을 해결하기 위하여 grib2 파일에 담겨 있는 여러 자료 중 특정 변수를 확인할 수 있는 ‘wgrib2’ 프로그램을 사용하였다. 아래 배시 쉘 스크립트처럼 내려 받은 파일들을 wgrib2 프로그램의 ‘-scan’ 또는 ‘-prob’ 명령어를 사용하여 확인하였을 때, Fig. 4와 같이 ‘FATAL ERROR’ 메시지가 출력되면 그 파일을 지우고 다시 내려 받는 방식으로 파일크기를 이용한 이상 유무 판별 방법의 문제점을 해결할 수 있다. 이와 관련한 wgrib2의 scan 명령어를 사용한 배시 쉘 스크립트는 Table 3과 같다.
|
Fig. 3. NCEP GFS files concurrently downloaded (a) abnormally in the cluster computer 1 and (b) normally in the cluster computer 2 operated by the Korea hydrographic and oceanographic agency. |

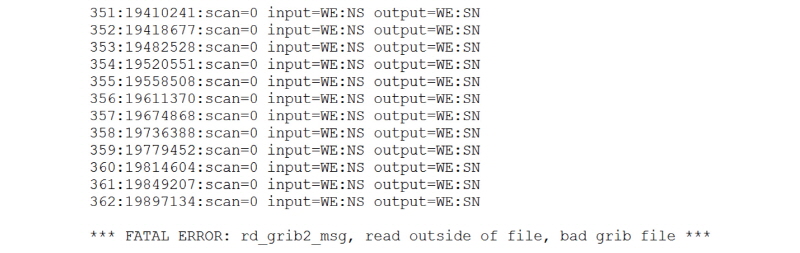
Table 3. A bash shell script for checking seamless NCEP files with grib2 format using ‘-scan’ comment of wgrib2 when they are downloaded |
|

3.2 해양예측자료 내려 받는 방법
지역해 해양예측모델에 필요한 입력자료 중 기상예측자료 다음으로 필요한 자료는 개방경계에 사용할 해양예측자료로 현재 ROMS 기반인 국립해양조사원의 예측시스템에서는 수온, 염분, 유속‧유향, 해수면높이와 같은 항목이 필요하다. 현재 국내에서는 주로 미국 GODAE에서 개발한 HYCOM의 전 지구 해양예측자료를 내려 받아 지역해 해양예측모델의 개방경계 입력자료로 사용하고 있다. 최적보간(optimal interpolation) 자료동화 기법을 사용하는 HYCOM(https://hycom.org/)은 (1/12)°의 수평해상도와 32개 연직 층으로 이루어진 해양예측자료를 NetCDF 파일형식으로 제공하고 있다. 그러나 HYCOM은 전 지구 영역의 해양예측자료를 제공하기 때문에 파일을 내려 받는데 많은 시간이 걸린다. 이러한 문제는 미국 NOAA의 ‘Pacific Marine Environmental Laboratory (PMEL)에서 개발한 Ferret (http://www.ferret.noaa.gov)이나 MathWorks사의 MATLAB 등의 쉘 스크립트를 이용하면 전체 파일을 받지 않고 원하는 영역만 선택적으로 받을 수 있어 손쉽게 파일 전송을 할 수 있다. 이것이 가능한 이유는 HYCOM에서 수치예측자료를 OPeNDAP (http://opendap.org/) 프로그램을 통해 제공하고 있기 때문이다. 이 OPeNDAP (Open-source Project for a Network Data Access Protocol)은 지구과학자들이 폭넓게 사용하는 자료 전송 체계와 통신규약(data transport architecture and protocol)으로, 이 통신규약은 인터넷에서 웹 서버와 사용자의 인터넷 브라우저 사이에 문서를 전송하기 위해 사용하는 HTTP (HyperText Transfer Protocol)를 바탕으로 한다. OPeNDAP 클라이언트(client) 컴퓨터 시스템을 통해 원격으로 서버 시스템에 접속하여 자료 전체가 아닌 원하는 영역과 예측항목에 대하여 MATLAB, Java, Python, IDL, NCO, Ferret, GrADS 등과 같은 프로그램을 쉘 스크립트에서 사용하여 사용자가 자료를 손쉽게 내려 받을 수 있다. 이러한 이점으로 OPeNDAP은 전 세계적으로 해양과 대기 자료 서비스에 널리 사용되고 있다.
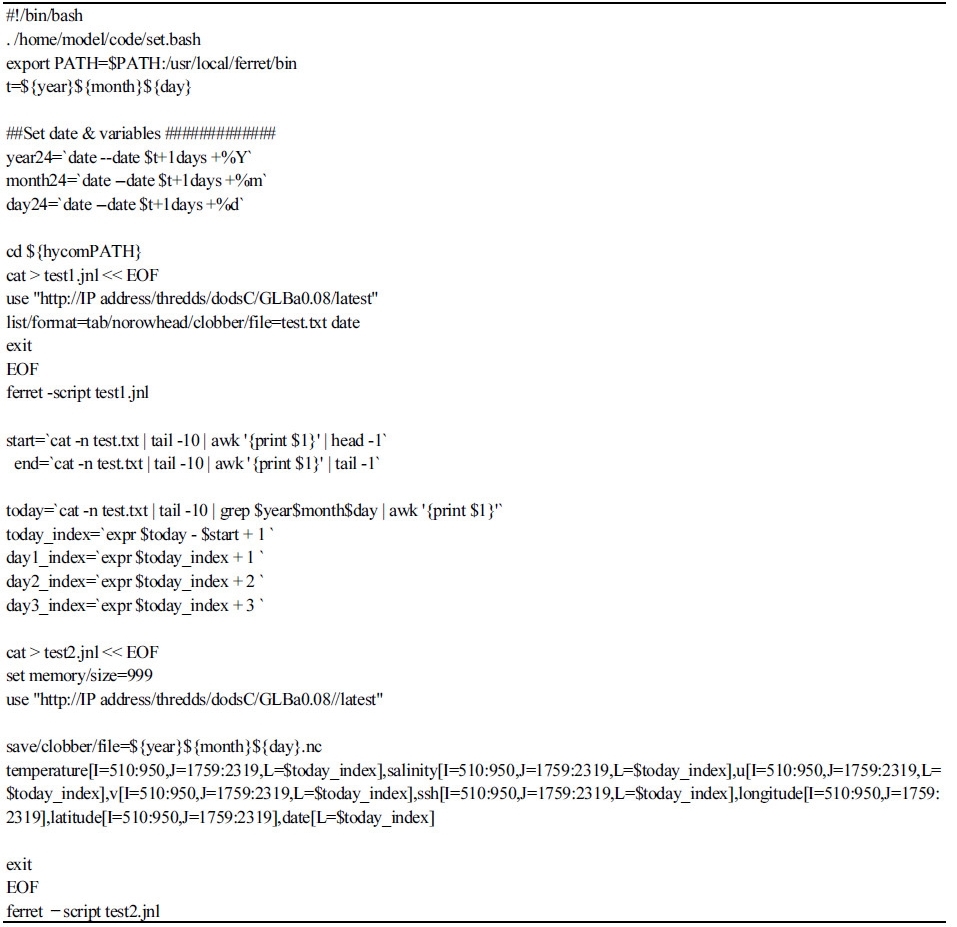
이 노트에서는 쉘 스크립트에서 Ferret과 MATLAB 프로그램들을 이용하여 원하는 시간, 영역과 예측변수들을 내려 받는 방법에 관해 제시하고자 한다. 첫 번째로 현재 국립해양조사원에서 사용하고 있는 방법인 Ferret 프로그램(http://www.ferret.noaa.gov/Ferret/)을 쉘 스크립트에서 이용하는 방법이다. NetCDF 파일형식의 예측결과 출력파일 중 원하는 시간, 영역과 예측변수들을 받는 경우에 대해, Table 4에 Ferret의 실행 스크립트 파일을 이용하여 HYCOM 예측자료를 내려 받을 때 사용되는 기본적인 명령어를 제시하였다. ‘use’ 명령어를 통해 불러온 자료는 기본적으로 4차원 배열의 형태를 갖고 있으며 I열은 경도, J열은 위도, K열은 높이, L열은 시간을 의미한다. 추출하고자 하는 영역은 경도(longitude)와 위도(latitude) 변수를 통해 좌표를 확인하면서 해당 범위를 찾는다. 하지만 시간은 공간적 영역처럼 이를 나타내는 변수가 없기 때문에 원하는 날짜가 위치하는 열을 알기 어렵다. 따라서 ‘list’ 명령어를 통해 불러온 자료의 날짜 순서를 확인하고 원하는 날짜가 L열을 기준으로 몇 번째에 있는지를 확인하였다. 그 후 ‘save/clobber/file’ 명령어를 사용하여 기존에 같은 이름으로 존재하는 파일 유무를 확인한 후 날짜를 파일 이름으로 하는 NetCDF 파일 형식으로 결과를 저장하였다.
Table 4. A bash shell script for downloading HYCOM data on specified area and specific variables using Ferret |
|
두 번째 방법인 MATLAB 역시 OPeNDAP 클라이언트 역할을 할 수 있다. 쉘 스크립트에서 MATLAB 2012a 이전 버전을 사용하여 OPeNDAP 서버에 접속해야 할 경우에는 ‘loaddap’이라는 별도의 도구(tool)를 설치해야 한다. 그러나 MATLAB 2012a 버전부터는 자체적으로 OPeNDAP을 지원하기 때문에 별도 프로그램 설치 없이 사용할 수 있다. 사용법 역시 기존에 MATLAB에서 지원하던 NetCDF toolbox를 이용하기 때문에 간단하며, 단지 다른 점은 로컬 폴더에 있는 파일이 아닌 OPeNDAP 서버에 있는 파일을 호출할 뿐이다. ‘ncdisp’ 명령으로 자료를 확인하고 ‘ncread’ 명령으로 원하는 변수, 시간, 공간적 영역만을 메모리에 불러들인 후 ‘nccreate’, ‘ncwrite’ 명령으로 새로운 파일에 저장한다. 원하는 시간, 공간적 영역을 찾는 방법도 Ferret과 다르지 않으므로 자세한 설명은 생략하고 Table 5에 관련 배시 쉘 스크립트를 제시하였다.
Table 5. A bash shell script for downloading HYCOM data on specified area and specific variables using Matlab |
|

Table 5. A bash shell script for downloading HYCOM data on specified area and specific variables using Matlab (Continued) |
|

쉘 스크립트에서 사용하는 Ferret과 MATLAB 모두 OPeNDAP 클라이언트로서 간단하고 편리한 도구이지만 각각 장․단점이 있다. Ferret의 장점은 작은 프로그램 용량 때문에 처리속도가 빠르고 시스템 자원을 적게 소모한다. 그러나 대소문자를 구분하지 않기 때문에 OPeNDAP 서버에서 자료를 내려 받을 때 저장한 NetCDF 파일명이 모두 대문자로 표시되는 단점이 있다. 반면에, MATLAB은 파일명 대․소문자 표현은 정확하나 6 GB에 달하는 큰 설치용량에 따른 로딩(loading) 속도와 시스템 연산자원 소모로 인한 느린 처리 속도가 단점이다. 또한 고가의 유료 프로그램이라는 점도 추후 시스템 유지관리에 부담을 줄 수 있다. 현재 국립해양조사원 해양예측시스템의 경우 외부에서 OPeNDAP을 이용하여 받는 자료 중 대․소문자 구분에 따른 문제는 없으므로 Ferret을 이용하여 외부 자료를 받고 있다.
4. 연산시스템 및 수치모델 수행 오류 알림 기능
신속한 해양예측정보 서비스를 위해서는 해양예측모델이 예정된 시각에 오류 없이 실행되어 예측자료가 생산되어야 한다. 그러나 실제 예측시스템 운용 시에는 다양한 이유로 수치모델 실행이 중단되는 일이 발생한다. 그 주요한 원인으로 태풍 등 강한 기상 외력 발생 시 급격한 해양 상태의 변화로 인한 수치모델의 불안정성, 수치예측시스템 오류, 통신 과부하로 인한 입력자료 내려 받기 중단과 원인 불명의 프로세스 중단, 정전ㆍ과열 등 외부환경의 변화에 따른 하드웨어의 가동 중단 등을 들 수 있다. 특히, 수치모델의 실행순서에 따라 선순위의 수치모델이 중단될 경우 개방경계 자료가 입력되지 않아 다음 순서의 수치모델 실행 지장까지 초래한다.
24시간 현업운영 시스템을 감시할 모니터링 인력이 없는 경우에 이러한 문제를 신속하게 해결하기 위해서는 우선적으로 담당자가 문제발생 상황을 즉시 인지할 수 있는 체계 마련이 필요하다. 국립해양조사원은 클러스터 컴퓨터 작동과 관련한 하드웨어적인 문제, 수치모델 연산 과정 중 발산, 소프트웨어적인 오류가 발생할 경우에 휴대전화 단문 메시지 서비스(SMS)를 이용하여 관련 담당자에게 이 문제들을 즉시 알리는 체계를 구축하였다.
먼저 하드웨어적인 문제에 대한 SMS 전달체계에 관해서 살펴본다. 보통 유닉스(UNIX) 계열의 운영체제를 사용하는 컴퓨터들은 주로 cron을 이용하여 수치모델들을 예약된 시각에 실행되도록 하는데 이를 설정, 수정하는 명령어가 ‘crontab’이다. 이 작업 스케줄러를 이용하여 클러스터 컴퓨터로부터 수치모델 결과를 신속하게 얻기 위해 여러 대의 컴퓨터를 사용하는 병렬처리 방법을 사용하여 수치모델을 수행한다. ‘crontab’ 작업 스케줄러를 이용한 방법은 별도의 다른 프로그램 사용 없이 손쉽게 수치모델을 수행 할 수 있으나 여러 클러스터 컴퓨터 중 사용 중인 한 노드(node)에 이상이 있을 경우에 수치모델이 수행되지 않는 단점이 있다. 또한 클러스터 컴퓨터는 발열이 발생하여 일정한 온도를 넘으면 컴퓨터 시스템이 멈추게 된다. 이 두 가지 경우에 신속한 조치를 위해서는 무엇보다 관련 담당자들이 상황을 빨리 파악할 수 있어야 한다.
이처럼, 클러스터 컴퓨터 중 노드들(nodes)의 작동 이상 유무를 파악하기 위하여 ‘crontab’를 이용하여 매 정시 후 50분에 각 노드의 상태(status)를 점검할 수 있도록 설정해 놓았다(Table 6). 이때 계산 노드(compute node)의 정보는 마스터 노드(master node)에 저장되는데, 이러한 점을 이용하여 마스터 노드에서는 정시마다(1시간마다) 노드의 상태를 확인하여 계산 노드에 문제가 발생할 시 ‘check node number'라는 메시지를 SMS를 이용하여 발송하도록 설정하였다(Table 7). 처음에 마스터 노드에서는 매 정시 마다 계산 노드로부터 받은 새로운 파일과 1시간 전에 받았던 파일에서 활성화되어 있는 노드와 비활성화되어 있는 노드를 비교하여 기존보다 활성화된 노드가 적을 경우 SMS를 발송하도록 설정하였다. 그러나 이렇게 설정한 경우 이상이 있는 노드가 정상으로 복구될 때까지 매 시간마다 SMS를 발송하는 문제가 발생하였다. 이 문제를 해결하기 위하여 이전과 활성노드의 개수가 같을 경우에는 SMS를 발송하지 않도록 하였다(Table 7).

Table 7. A bash shell script for sending the Short Message Service (SMS) when any node of a cluster system is down |
|

또한 클러스터 컴퓨터는 매일 24시간 운영되며 고속 연산을 수행하기 때문에 발열이 상당하므로 이를 조절해 줄 수 있는 항온항습 장치의 역할이 매우 중요하다. 항온항습장치에 문제가 발생하여 클러스터 컴퓨터 내부의 온도가 급상승할 경우에 시스템은 멈추게 된다. 이러한 문제를 미연에 방지하기 위해 매 시간마다 클러스터 컴퓨터의 앞쪽에 설치되어 있는 흡입 온도 감지기(inlet temperature sensor)를 통해 흡입공기의 온도가 설정한 임계값(38°C) 이상일 경우에 담당자에게 문자 메시지를 발송하도록 하였다(Table 8). 일반적으로 흡입 공기의 온도가 40°C 이상이 되면 하드웨어가 자체적으로 전원이 차단되므로 이를 고려하여 임계 온도는 40°C 미만으로 설정되어야 한다.

하드웨어적인 문제 발생 시 SMS 전달체계에 이어서, 수치모델인 소프트웨어의 정상작동 여부를 확인하기 위해 Table 9과 같이 수치모델의 정상작동 상태를 확인하는 스크립트를 통해 수치예측자료 정상 생산 유무를 확인할 수 있도록 하였다. 2016년 12월 말 현재 국립해양조사원에서는 ROMS 수치모델을 사용한 15종의 광역․지역해․연안 수치모델들이 구축․운영되고 있다. 각 수치모델에서 출력되는 NetCDF 파일의 개수와 크기로 수치모델 정상작용 여부를 확인하여 이상이 있을 경우에 SMS를 이용하여 메시지를 발송하도록 하였다.

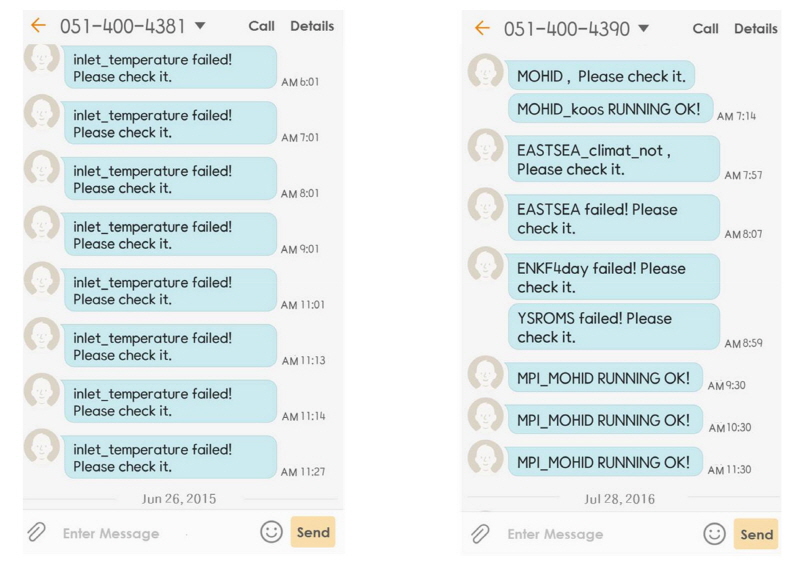
예를 들어, 동해예측모델(ES)은 매일 한 시간 간격으로 3일간(00∼72 hr) 예측하여 73개의 일정한 크기의 NetCDF 파일을 생산하고 있다. 하지만 수치모델 수행에 문제가 생겨 73개의 파일이 생산되지 않거나 이중 한 개의 파일이라도 파일의 크기가 작을 경우에 SMS을 통해서 메세지를 전송하는 체계가 작동된다. 이때 시스템에 등록된 휴대전화 번호로 오류 메시지가 전송되어 관련 담당자가 상황을 즉시 인지하고 즉각적인 조치를 취할 수 있도록 한다. Fig. 5(a)는 클러스터 시스템의 흡입 공기의 온도가 상승하여 실제 담당자에게 SMS를 이용하여 전송된 메시지 내용이며, Fig. 5(b)는 여러 수치예측모델들이 정상적으로 작동하지 않았을 때 관련 담당자들에게 SMS로 오류 메시지를 보낸 결과를 보여주고 있다.
5. 요 약
이 노트는 2012년부터 2016년까지 국립해양조사원 내에서 현업용 지역해(동해, 황․동중국해) 해양예측시스템 운영체계를 구축하면서 직면했던 여러 기술적 문제점들을 해결하면서 확보한 기술 중, (1) 끊임없는 해양예측 자료 생산 전략, (2) 외부 해양․기상예측자료를 내려 받는 방법과 (3) 시스템 오류 알림 방법을 담고 있다. 이 노트에서 다룬 내용들이 다른 분야 커뮤니티(community)에서 일반적으로 사용되거나 잘 알려진 내용들일 수 있지만, 해양 수치예측 분야에서는 아직 잘 활용되지 못하고 있는 것들이다. 이 연구가 해양 수치예측 연구자와 실무자들이 현업용 해양예측시스템 운영하는 데에 필요한 기술적인 내용을 처음으로 구체적으로 다루었다는 점에서 의의가 있다. 해양 수치예측시스템을 구축할 때 이 연구에서 제시한 방법들을 활용한다면 시행착오를 줄일 수 있어 유용할 것으로 생각된다.
한편 국립해양조사원은 2012년부터 현재까지 고해상도(3 km 수평해상도) 동해 예측모델뿐만 아니라 동일한 수평해상도의 황․동중국해 예측모델에 대한 자료동화 기법의 적용 및 개선 연구를 추진하고 있다. 이들 지역해 해양예측모델에 인공위성 표면수온자료와 인공위성 고도계 자료, 그 밖에 국립해양조사원과 국립수산과학원에서 관측한 연직 층별 수온염분(CTD)자료, 아르고 플로트(Argo float) 자료를 동화하여 수행하는 체계가 확립되어 있다. 앞으로 우리나라 주변해역에 대한 정확도 높은 고해상도 지역해 예측자료가 매일 생산되어 제공될 것이다. 이 연구에서 제시한 기술적 방법은 향후 연안 해양예측시스템을 구축하고자 하는 기관들이나 연구자들에게 유용한 참고자료가 될 것이다. 다음 기술노트는 국립해양조사원에서 구축하여 운용 중인 해양예측모델 자료동화 체계와 함께 수치예측모델 코딩 최적화에 관해 소개할 계획이다.
